Build A The Web
Introduction
This is Build A The Web, a book devoted to taking us, people with basic programming and computer knowledge, and upgrading us into web programmers. I am Cube Drone and I'll be your host.
The best kind of textbook about the web is made out of HTML and filled with media and links to other content. That is what the web is all about, not dusty ol' textbooks that are no longer valid because they cover a version of the web that went obsolete nine years ago.
This book was last updated May 1, 2020. If that's a long time ago, I might have died. Avenge me!

This work is licensed under a
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
This site, and all of the resources used to generate this site, including class materials and examples, are available at https://github.com/cube-drone/buildatheweb. That's also a good place to comment, suggest updates, file bugs, and generally improve the book if you feel that it needs some attention.
What are we going to learn?
Becoming a web developer involves a lot of skills! This handy Web Developer Roadmap lays them out in a way that's pretty sensible, and we're going to try our best to carve a path through many of these skills that leaves us ready to build some cool websites.
Okay, let's get started. Are you ready?
Chapter 1: Request, Response
Our first chapter is going to focus on what happens behind the scenes when we make a web request. What that means is a crash course in computer networking.
Uniform Resource Locators
Let's start by looking at what happens when we crack open a web browser and type in:
https://en.wikipedia.org/w/index.php?title=Blinkenlights&action=edit#Etymology
This is a URL, which stands for Uniform Resource Locator.
This URL uniquely identifies a document somewhere on someone else's computer that we are going to request from that computer.
This divides into protocol, domain name, path, parameters, fragment, locus, and spindle. Memorize all of these terms now.
Dissecting a URL
Protocol
https://en.wikipedia.org/w/index.php?title=Blinkenlights&action=edit#Etymology
The protocol describes how to connect.
Domain Name
https://en.wikipedia.org/w/index.php?title=Blinkenlights&action=edit#Etymology
The domain name describes where to connect to.
Path
https://en.wikipedia.org/w/index.php?title=Blinkenlights&action=edit#Etymology
The path describes what is being requested.
Parameters
https://en.wikipedia.org/w/index.php?title=Blinkenlights&action=edit#Etymology
The parameters describes extra arguments for the thing being requested.
Fragment
https://en.wikipedia.org/w/index.php?title=Blinkenlights&action=edit#Etymology
The fragment describe a specific part of the document that we want to look at.
Locus & Spindle
the locus and spindle were in your heart the entire time
This is just a bunch of words, describing where we think our document is. How do we actually get that document?
Transport Control Protocol / Internet Protocol
Communicating with a far away computer is a process fraught with interesting problems. Problems like:
- How do we make sure that messages reliably arrive?
- How do we make sure that messages arrive in the right order?
- How does our computer communicate with our router?
- How does our router communicate with our modem?
- How do we get messages to travel across a thin strip of copper, or fiberoptic cable, at all?
Most of these problems are quite complicated — and the lower level we get, the more likely it is that we'll need to consult an electrical engineer to explain signal processing theory to us. Believe me, that is the last thing that we want.
Fortunately, smart people have already solved most of these problems for us. The solutions to these problems stack up on top of another — at the bottom, electrical engineers figuring out how to send messages across wires, at the top, math PhDs figuring out how to make sure that messages arrive reliably in a fixed order.
We have two protocols at the very top of the stack that define how we communicate between computers — IP, the Internet Protocol, which defines how we send messages across the network, and TCP, the Transport Control Protocol, which makes sure that our messsages completely arrive, in the right order, and uncorrupted.
Protocol & Stack
I'm going to say the word protocol a lot, and it's probably important that I establish what that means. In Computing Science, we learn the difference between an algorithm and a program — an algorithm describes a specific way of solving a problem, whereas a program is the actual code that we need to run the algorithm. We could have five different programs, all implementing the same algorithm.
A protocol is an algorithm for communication. It delineates the rules of communication.
In the same way that a program is an implementation of an algorithm, a stack is an implementation of a protocol. A protocol is an algorithm, and a stack is a program to implement a protocol. So, in order to run TCP/IP, our computer runs the TCP/IP stack, which implements the TCP/IP protocol.
IP Address & Sockets
The abstraction presented by TCP/IP
is simple: every computer has an IP address.
An IP address looks like this: 192.0.2.0 — or, like this:
2001:DB80:c501:17ef:a063:a37f:3803:5c1a. These are just
identifiers that communicate a unique identity for the computer in question.
If we know our IP address, and the IP address of the computer that we want to communicate with, and that other computer is online, we can trust that IP will get the message to that computer. We can use TCP to open a socket to a specific port on our target computer.
Giant Walls of Plugs
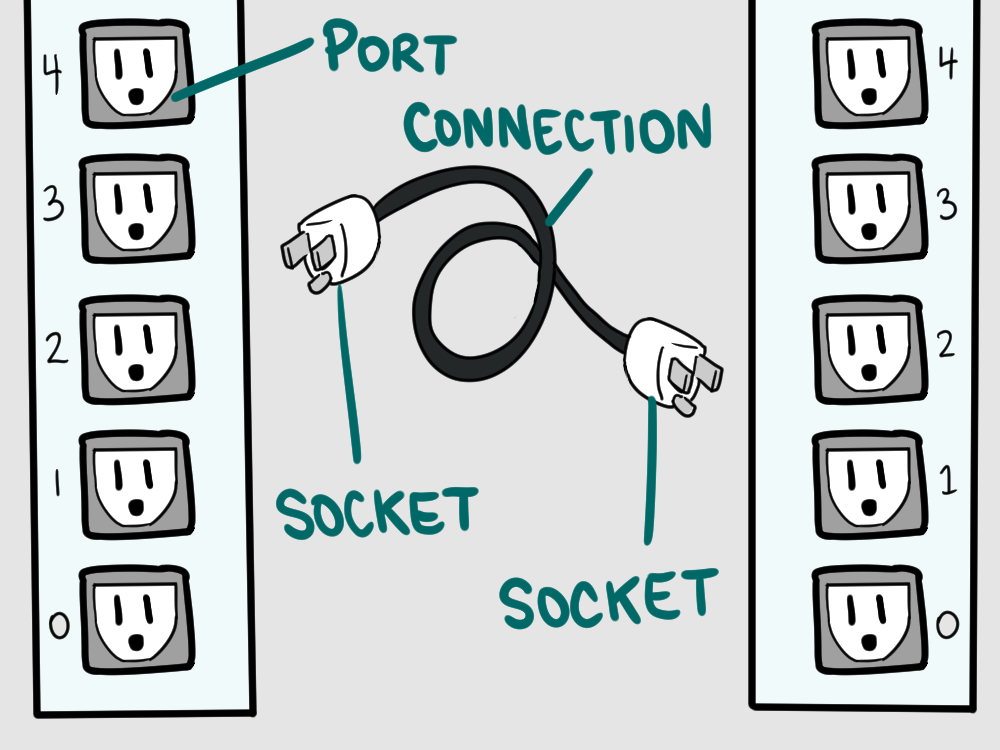
Imagine these computers like giant walls of plugs — or ports — and when we open a connection, TCP creates a two way communication link between two ports with a socket on each end.
There are thousands of these ports — they're numbered from 1 to 65,535. In order to keep things tidy, each different protocol that runs on top of TCP usually runs on a different port. Of course, most computers aren't communicating on all of these ports at once — in fact, there are six ports that, on most computers, get more use than all of the rest of them combined:
- 25, for the Simple Mail Transfer Protocol (SMTP)
- 53, for the Domain Name System (DNS)
- 67 and 68 for the Dynamic Host Configuration Protocol (DHCP)
- 80 for the HyperText Transfer Protocol (HTTP)
- 443, for the HyperText Transfer Protocol over Transport Layer Security (HTTPS)
We're going to cover all of these protocols in detail at one point or another. editor's note: no, we're not
For every port that we could contact on a remote computer, there's a program on the remote computer that's running, listening, and potentially responding to our requests.
Server vs. Client
A computer that stays connected to the internet all of the time and responds to these requests is called a server, and server programming is half of the battle of web programming. The second half is client programming, which describes the parts of the transaction that occur on the customer's side of things.
DHCP
In order to communicate with a remote server, then, we need three things — our IP address, their IP address, and a port number, to communicate with.
First of all, let's talk about how we got our IP Address.
Well, the short answer is, our computer already knows its IP address. We just ask.
How did our computer get its IP address? Well, when we connected it to the router — either via WiFi or by plugging it in — it communicated to the router, using DHCP, the Dynamic Host Configuration Protocol, where our computer asked the router to assign it an IP Address.
Then, how did the router that gave us an IP address get its own IP address? Well, when we connected the router to the internet, either by plugging it in to a modem or by plugging it in to another link in the network, it also communicated to a router, and communicated using DHCP. It asked "What is my IP?".
Network Address Translation
If we ask our computer to tell us its
IP address, it'll probably report something
that starts with 10.0 or 192.168 — but, if we go to
Google and ask "what is my IP?",
it'll tell us a completely different
IP address.
What gives? How can our computer have more than one IP address?
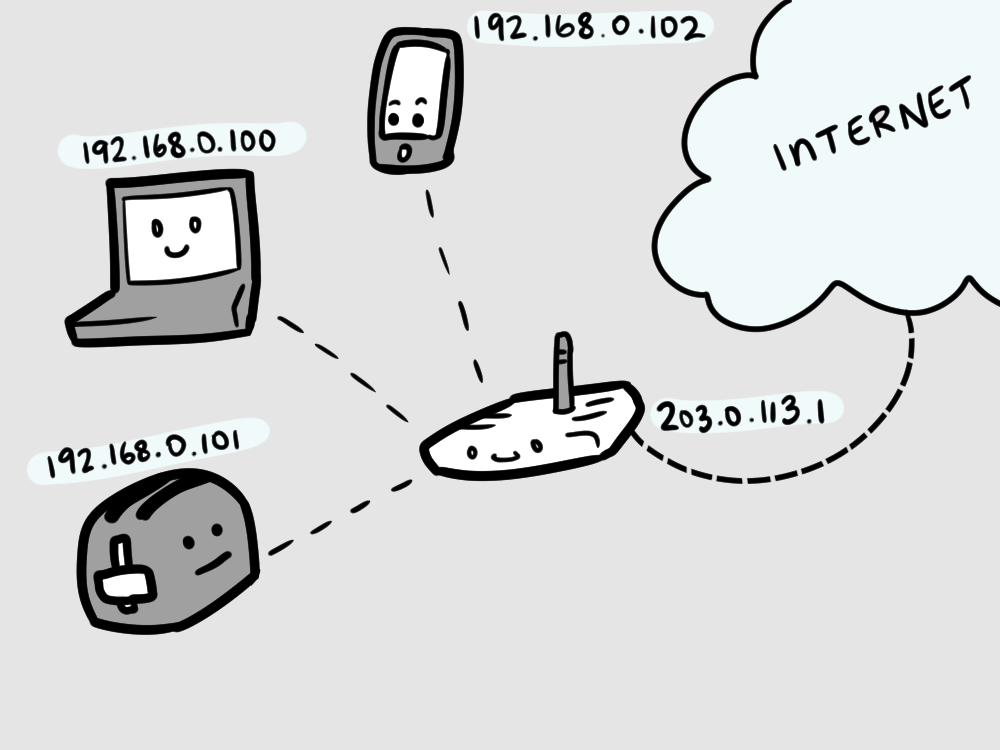
As part of our deal with our ISPs, we usually get just one IP address. Just the one. Presumably, we have more than one device in our home — a computer, a cel phone, a laptop, a second computer, a smart TV, a toaster that connects to the internet for some reason, a third computer, a toothbrush that connects to the internet for some reason, things have really gone out of control lately.
All of these devices need to share the one IP address, so, our router creates a little private
network, just for us, in our home. In this private network, any computer can have any
IP address
that it wants. By convention, the IP
addresses for use in private networks start with 192.168
or 10.0. Then, when we're connecting to the outside world, our router translates
our IP address in the private network into our public
IP address.
This is NAT, Network Address Translation.
The router creates a private network for all of our devices and assigns them local IP addresses.
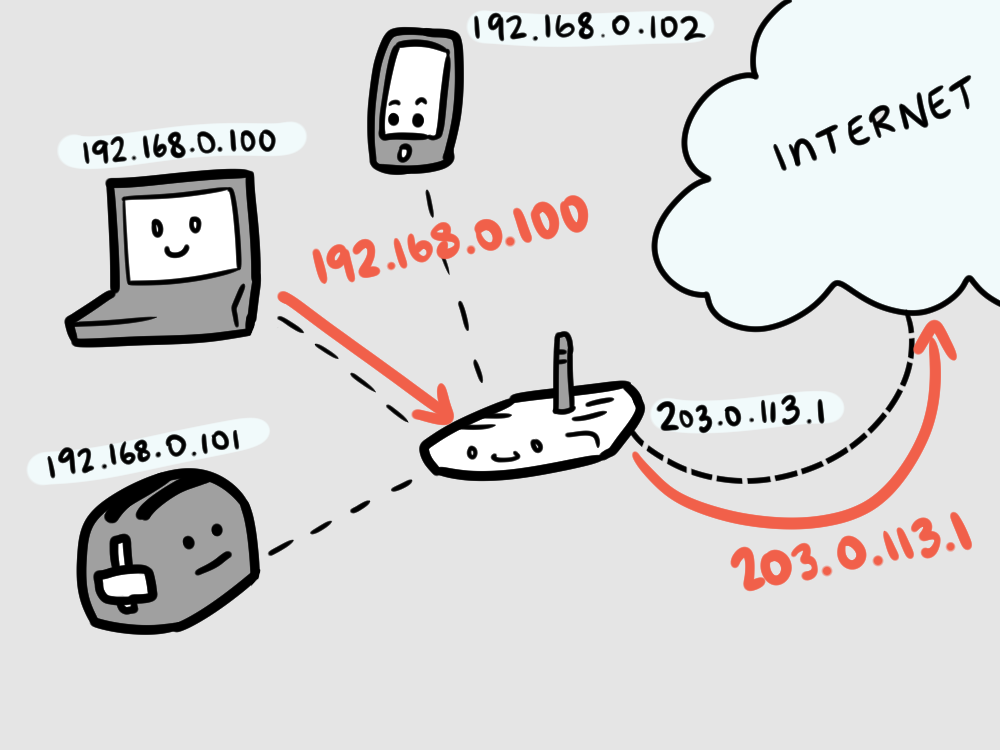
When our devices make requests to the internet, the router translates them into the public-facing IP address.
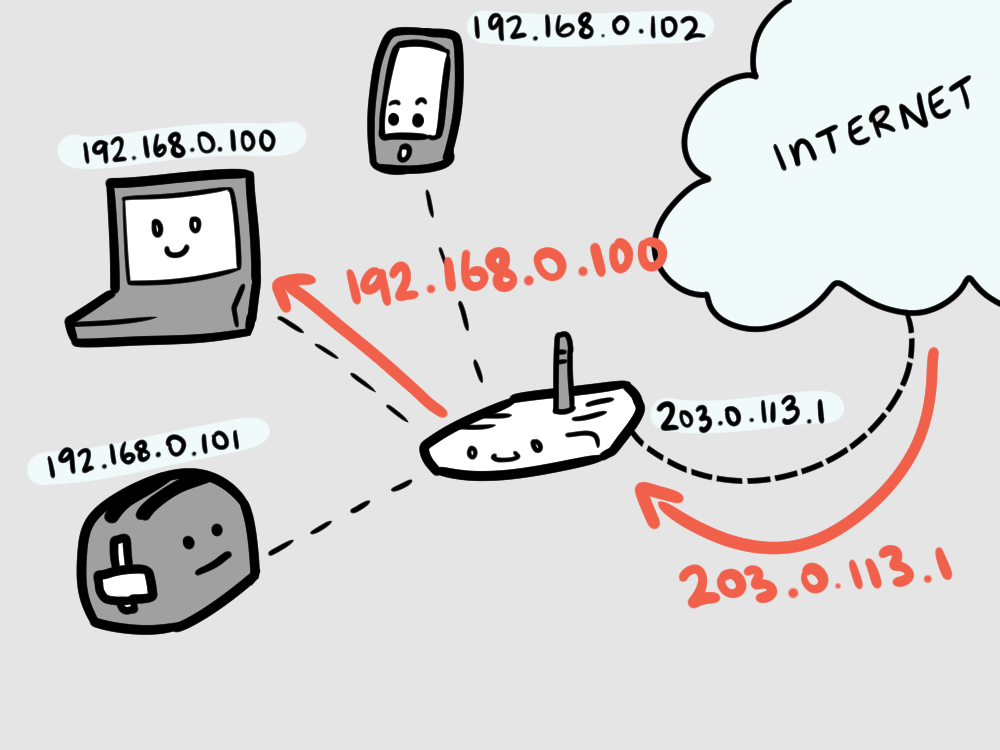
When the internet responds, the router remembers who requested the content and forwards the response back to that IP address.
Domain Name System
In order to communicate with a server, we need both our own IP address and the IP address of the computer that we want to communicate with.
We have our own IP address — now we need to find the address of the server that we want to talk to.
Let's look at the link we're trying to access.
https://en.wikipedia.org/w/index.php?title=Blinkenlights&action=edit#Etymology
There's no IP address anywhere in this link. There is a domain name,
en.wikipedia.org
In order to find the IP address for this server, we're going to have to start by consulting a DNS server. DNS stands for Domain Name System, and the process of converting a domain name into an IP address is called name resolution.
How do we know where the DNS server is? When we use DHCP to connect to WiFi, it also provides us with the IP address of the nearest DNS server, which is usually being maintained by our ISP. Acronyms!
Turkish Protesters

Google also maintains a public
DNS
server at the address 8.8.8.8, which is good to know
in case our local
DNS server ever goes down or is
interfered with by a totalitarian government.
So our computer sends a request to the
DNS server,
asking where to find en.wikipedia.org.
If the server already knows where en.wikipedia.org is, then it responds with the
IP address. Let's imagine, though, that the server doesn't know.
DNS Root servers are distributed all over the globe, and they keep track of exactly one thing: the IP addresses of the computers reponsible for the recordkeeping of top level domains, like
.com.net.org.photo.click.ninja.unicorn.fun.ooo.plumbing.oh my god top level domains are just getting dumber and dumber
So, the DNS server looks at the domain name we've given it —
en.wikipedia.org —
sends a request to the root server, and asks
"which servers can I ask about .org records?"
The root server will reply with a list of IP addresses responsible for .org records. These are the addresses of Top Level Domain Servers, which are maintained by Domain Registrars. We can pay these people about ten US dollars a year to create and maintain a record for us, so long as nobody else has claimed that domain name already. For a pittance, I now own http://lassam.net.
Finally, the DNS server queries the wikipedia nameservers, asking them
where they can find en.
If we paid a registrar to put up a domain name for us,
they'll usually throw in a nameserver for free —
all we have to do is write some DNS
rules that tell the nameserver what
IP address we want to point at.
DNS rules are written in a cryptic language that contains records
with names like A, MX, AAAA,
and AAAAAAAAAAAAAAAAHH SPIDERS —
I'm sorry, there was a spider next to the keyboard.
So, Wikipedia's nameservers report that en.wikipedia.org is
located at, say, 203.0.113.98.
Finally, after that entire protracted process, we know where wikipedia is.
HyperText Transfer Protocol
Our next step is to use TCP/IP to create a connection between our IP address, and the IP address that we just resolved from DNS.
There's only one thing left that we need — a port number. We also didn't specify a port number as part of the URL, but we did specify a protocol, HTTPS — the HyperText Transfer Protocol feat. Transport Layer Security — and when we specify a protocol without a port number, our connection automatically goes to the default port for that protocol. In the case of HTTPS, that's 443.
The HyperText Transfer Protocol (HTTP) is the protocol responsible for moving documents around. Request a document? Get a document. The rules for that are laid out in the HyperText Transfer Protocol, which is the protocol that powers pretty much the entire web as we know it.
Our URL's protocol is HTTPS, though, not just HTTP. The difference is slight but important — HTTPS is the same as HTTP, but over a connection encrypted with Transport Layer Security (TLS). This prevents J. Random Hacker from watching every HTTP request that goes by.
Once we've created this encrypted communication path between our computer and the faraway server, we need to construct a HTTP Request. It'll look something like this:
GET /w/index.php?title=Blinkenlights&action=edit#Etymology HTTP/1.1 Host: en.wikipedia.org
This is a request to GET whatever's at the path
of the URL we provided to our browser.
It also includes Headers with the request — sets of key and value that communicate extra information to the server. In this case, the only header we've included is "Host".
The server will receive this request, and respond with a HTTP Response containing the sweet webpage we've been looking for this entire time.
Virtually everything in web programming happens in the space between the HTTP request and the HTTP response. Figuring out how to respond, quickly, with the right stuff is the meat and potatoes of web programming. This bit, right here. It's all the marbles. Empires have risen and fallen, all dependant on the simple gap of how a server converts this HTTP request into a HTTP response.
And then, Wikipedia responds. The full HTTP response is several pages long, we can look at it here. In order to keep my book neat and tidy, though, I'm going to concoct a fake response for the sake of example:
HTTP/1.1 200 OK
Content-language: en
Content-type: text/html; charset=UTF-8
X-Clacks-Overhead: GNU Terry Pratchett
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Definitely Wikipedia</title>
</head>
<body>
<h1>This is totally Wikipedia.</h1>
<p> Hi there. I am Bob Wikipedia and you are at my website.
It’s still under construction but I am pretty sure it will be done by 1998.</p>
<img src=”https://media0.giphy.com/media/K5Yn9JCXcrXr2/giphy.gif”>
</body>
</html>
It opens with the version of
HTTP that's currently running,
as well as a HTTP Status Code.
So long as the HTTP Status Code is 200 OK we're good to go.
A Brief And Mostly Inaccurate Reference Chart for HTTP Status Codes

A more accurate look at HTTP status codes can be found here.
Alternatively, pictures of cats matching every HTTP status code exist at http.cat.
After the HTTP version and status code, there are Headers again. These headers describe important properties of the file that's been returned.
Content-language: en Content-type: text/html; charset=UTF-8 X-Clacks-Overhead: GNU Terry Pratchett
Most headers are defined in the protocol itself,
but we can add
any headers that we want by starting them with X-,
which is how we can sneak in the clacks.
After the HTTP version and status code, we get into a big patch
of HTML.
How do we know that it's
HTML? Well, the Content-type
header referred to this as text/html, so we can be
pretty sure that we've got a big handful of
HTML.
Hypertext Markup Language
I'm going to do a dramatic reading of a passage from "In The Beginning Was The Command Line". Despite being almost 20 years old, it's a stonkingly accurate diatribe on computer culture and a fun historical record from the before times.
This crud is called HTML (HyperText Markup Language) and it is basically a very simple programming language instructing your web browser how to draw a page on a screen. Anyone can learn HTML and many people do. The important thing is that no matter what splendid multimedia web pages they might represent, HTML files are just telegrams.
When Ronald Reagan was a radio announcer, he used to call baseball games by reading the terse descriptions that trickled in over the telegraph wire and were printed out on a paper tape. He would sit there, all by himself in a padded room with a microphone, and the paper tape would eke out of the machine and crawl over the palm of his hand printed with cryptic abbreviations. If the count went to three and two, Reagan would describe the scene as he saw it in his mind's eye: "The brawny left-hander steps out of the batter's box to wipe the sweat from his brow. The umpire steps forward to sweep the dirt from home plate." and so on. When the cryptogram on the paper tape announced a base hit, he would whack the edge of the table with a pencil, creating a little sound effect, and describe the arc of the ball as if he could actually see it. His listeners, many of whom presumably thought that Reagan was actually at the ballpark watching the game, would reconstruct the scene in their minds according to his descriptions.
This is exactly how the World Wide Web works: the HTML files are the pithy description on the paper tape, and your Web browser is Ronald Reagan.
So, the HTML that Wikipedia has returned to us contains a description of the content that we're looking at, and then our web browser renders it into a webpage.
It would seem like, here, our journey is complete. We've made a round trip between our device and the server, and we're done — but, not quite! When the browser renderer gets to this part of the HTML:
<img src=”https://media0.giphy.com/media/K5Yn9JCXcrXr2/giphy.gif”/>
This image tag references content that exists at another URL. And so, we kick off this entire process again, from start to finish, to get whatever it is at that new address. The trick is, though, instead of sending us HTML, this server will respond with an animated image. Modern web-pages may require dozens of requests to various images and scripts before they're completely rendered.
Chapter 1 Summary
Every browser request–response goes a little something like this:
- Our browser uses DNS to resolve the URL's domain into an IP address.
- Our browser uses TCP to create a two-way connection with the server at that IP address.
- If the URL's protocol is HTTPS, then a TLS connection is made to the server.
- Our browser sends a HTTP request to the server.
- The server does some stuff.
- A HTTP response is sent back to us, containing a document.
- If that document is HTML, the browser will render that HTML into a webpage.
- If that document contains other URLs, the browser will create new requests for each of them.
Chapter 2: HyperText
We've talked about HyperText Transfer Protocol and HyperText Markup Language, so what in the blue blazes is HyperText?
As with most things, there's a lot of history and nuance behind the term, and also as with most things, the way that most people understand the term completely discards all of that history and nuance: HyperText is text with a whack of extra stuff strapped on, links and images and style and fonts and videos of cats and scripts.
Links and URLs
There are two big questions of hypertext
- How do we represent a link to another document in a document?
- How do we represent a diverse array of multimedia content in a simple file format?
The answer to both of these questions is the humble URL. A URL can represent a link to any sort of content.
So HTML documents are littered with URLs, both as links to other documents and as a means to embed multimedia content in a wide variety of formats.
Text Files and Markup Language
Under the hood, all file formats are just binary narrowly disguised as something else.
When we think of file formats for text, our first thought might be of Word, from Microsoft Office — a format that also contains information about how to properly render the document, fonts, document layout details, and much much more. Unfortunately, Word file formats — of which there are several at this point — are legendary tarpits of horrendous complexity, closed off so that they can only be understood by Microsoft engineers, a hideous conglomeration of text and binary that make Word the file format equivalent of the last 15 minutes of Akira.

Pictured: An OpenOffice developer trying to make sense of Word's file format.
A common way to manage the complexity associated with complicated documents are to represent them as simple plain-text files. It's not quite as simple and efficient as storing documents in pure binary representations, but the file formats end up being human-readable by anybody with a text editor, which is great for the clarity and interoperability of the format.
But the problem of plaintext becomes quickly clear: it doesn't support presentational elements very well. How do you include a list of items? A table? An image? How do you define font sizes and margin widths? There need to be rules that a computer can follow to take a plaintext file and turn it into a proper document. Furthermore, we shouldn't show these rules to the user. A markup language allows us to mark the text with additional information that isn't shown to the user, but indicates additional information like emphasis, color, and font.
or, to look at that last line, again, in Hypertext Markup Language:
A <strong>markup language</strong> allows us to mark
the text with additional information that isn't shown
to the user, but indicates additional information
like <em>emphasis</em>,
<span style='color:red;'>color</span>, and
<span style='font-family:chunk'>font</strong>.
HTML — Hypertext Markup Language — is not the only markup language — many of them exist.
HTML is based on a language called SGML, which was based on a language called GML, which was created at IBM in the 1970 as a documentation language.
Technically, HTML qualified as a subclass of SGML until the introduction of HTML5, which finally cut all remaining ties with the old standard.
Some Other Markup Languages
Another child of SGML is XML. While HTML was intended to be a representation of documents and the sort of data that would commonly appear in documents — tables, images and such — XML is a similar format that was designed as a general-purpose markup language for any kind of data.
Some XML might look like this:
<employee>
<name>Barry Fudgechampion</name>
<age>27</age>
<salary>Low</salary>
<odor>Potent</odor>
</employee>
Markdown is a markup language that's designed to be interoperable with HTML and easy for humans to read and edit, even when it's just plain text.
Some Markdown might look like this:
# Laziness, Impatience, and Hubris
"We will encourage you to develop the three great virtues of a programmer:
laziness, impatience, and hubris." -- Larry Wall, Programming Perl (1st edition)
Take a look at [this link](http://wiki.c2.com/?LazinessImpatienceHubris)
for more information.
## Laziness
The quality that makes you go to great effort to reduce overall energy expenditure.
It makes you write labor-saving programs that other people will find useful,
and document what you wrote so you don't have to answer so many questions about it.
Hence, the first great virtue of a programmer.
Also hence, this book. See also _impatience and hubris_.
## Impatience
The anger you feel when the computer is being lazy.
This makes you write programs that don't just react to your needs,
but actually anticipate them.
Or at least pretend to. Hence, the second great virtue of a programmer.
See also _laziness and hubris_.
## Hubris
Excessive pride, the sort of thing Zeus zaps you for.
Also the quality that makes you write (and maintain) programs that other people won't
want to say bad things about. Hence, the third great virtue of a programmer.
See also _laziness and impatience_.
JSON (Javascript Object Notation) is a quite simple markup language that's also valid Javascript, which makes it very easy for the language Javascript to handle.
Some JSON might look like this:
{name: "Barry Fudgechampion",
age: 27,
salary: "Low",
odor: "Potent"}
YAML (Yet Another Markup Language) is a markup language that's designed to be easy for humans to read and edit, designed to represent complex objects.
Some YAML might look like this:
- name: Barry Fudgechampion
age: 27
salary: Low
data: |
There once was a short man from Ealing
Who got on a bus to Darjeeling
It said on the door
"Please don't spit on the floor"
So he carefully spat on the ceiling
Some of these markup languages are easier for humans to read. Some of them are easier to code with. Some of them are more stict and some of them are less strict. Some of them are intended to represent data and some of them are intended to represent documents. But they are all a way to use plain text to represent something more complicated than plain text.
All of these different markup langauges are good for different purposes.
- HTML is good for representing multimedia documents that link to one another.
- JSON is good for transmitting data in a simple format between systems.
- YAML is good for human-written data, like configuration files.
- Markdown is good for human-written multimedia documents that are still readable in their text format.
- XML is good for representing objects that have a strictly defined format.
Bad news: You're probably going to have to learn all of these markup languages at one point or another.
Good news: They're not very difficult to learn!
Character Encoding
It's possible, through the use of these different markup languages, to represent just about anything as a plain-text file.
"A text file" is a little bit disingenuous, though. There's no such thing as just a "text file". A text file is, under the hood, a series of characters represented as binary data.
How, then, do we represent a text file as binary data?
There are numerous schemes for converting character data into binary data, and these schemes are known as character encodings.
ASCII
An early common character encoding is ASCII — which is simple — 7 bits can make 128 different combinations. That's more than enough room for all 26 latin alphabet characters in both lowercase and uppercase, and all of the numbers and symbols on a standard US keyboard, with room left over for some control codes like "new line", "tab", "alert", and "bell".
Here's a segment of the ASCII table:
| Decimal | Hex | Binary | Character |
|---|---|---|---|
| 96 | 60 | 01100000 | ` |
| 97 | 61 | 01100001 | a |
| 98 | 62 | 01100010 | b |
| 99 | 62 | 01100011 | c |
| 100 | 63 | 01100100 | d |
The full table, as well as more additional detail than you could possibly imagine, is available at Wikipedia.
hello, world in ASCII would read as:
1101000 h
1100101 e
1101100 l
1101100 l
1101111 o
0101100 ,
0100000
1110111 w
1101111 o
1110010 r
1101100 l
1100100 d
ASCII was enormously popular for a very long time — but the big problem with ASCII is that 128 characters are not enough characters to encompass the entire character set of all available human languages.
ISO-8859
7 bits is all well and good, but 8 bits would double the amount of character space available to us — and 8 bits makes a byte, which makes it really easy to remember "A character is about a byte".
What characters do we cram into that extra 128 spaces on the table, though? Even English contains a bouquet of words that use diacritical marks.
How do we decide whether to include the spanish ñ, so that we can say "jalapeño" or the french ç, so that we can say "soupçon" and "façade"?
And what about characters that are used extensively by unimportant languages like every other human language?
One idea was to use ASCII for the first 128 characters, and then, in the other 128 characters, fit all of the extra bits required for groups of different languages. Group 1 would contain a bevy of characters for latin-based languages like English, French, German, Italian, Portugese. Group 2 would have characters useful for central european languages like Polish, Czech, and Hungarian. This scheme would be extensible, allowing new groups to be added — and, to date, there are sixteen.
This scheme was called ISO-8859, and it enjoyed common usage through most of the 90s and 00s, and group 1, ISO-8859-1, commonly known as latin-1, became one of the world's most common character encodings.
Here's ñello, world in latin-1:
11110001 ñ
01100101 e
01101100 l
01101100 l
01101111 o
00101100 ,
00100000
01110111 w
01101111 o
01110010 r
01101100 l
01100100 d
The only character that stands out is ñ, which lives in the last-half of the encoding, so it starts with a one. All of the other characters are the equivalent to their ASCII-encodings.
� � � � what even
When downloading a HTML file from the internet using HTTP, the HTTP server is supposed to accurately report the character encoding that the text is using.
Sometimes, though, the HTTP server sends the wrong character encoding. Stupid HTTP server. When most browsers can't understand a character, they'll display the � character, which is the browser equivalent of going ¯\_(ツ)_/¯.
It's getting harder and harder to find webpages with serious encoding errors but fortunately Eric S. Raymond hasn't updated his Jargon File in a long while, so we can still find some.
There's a bug that used to be common — Windows used an encoding in the Windows-98 era, called Windows 1252 that was commonly confused for latin-1.
Webpages would report that they were returning latin-1 when they were actually returning windows-1252, and the result would be web-pages lined with the � character. It doesn't happen much any more, because the world has been standardizing on a new encoding: UTF-8.
But before we get to UTF-8 we have to talk about Unicode.
Unicode
The problem with all of these character schemes is that they have to be efficient.
Nobody is interested in a character encoding scheme that has room for all of the different possible characters, because it's just not practical for every single character to take several bytes of space to represent.
Character encoding is hard, though. For one thing, there's a lot of characters that are very easy to confuse for one another.
"Do you know what would be nice", I imagine someone saying. "It would be nice if we just had a list of every single character and gave each one of them a number."
"That's not a character encoding scheme", said someone else in this hypothetical scenario. "There's not even any instructions for how to convert that into a binary representation, that's just a big list of all of the possible characters, and each of them have a unique number."
"It doesn't need to be a whole character encoding scheme. It'd just be nice if we had a unique number for each character."
So, that's what Unicode is — not a binary encoding scheme at all, really, just a list of all of the characters and a unique number for each of them. This unique number is called a code point.
The entire Unicode character table is enormous. "A" is 41, "Â" is 194, "௵" is 3061. "♞" is 9822. There's space for everything, including every character in Chinese, Japanese, and Korean, and there are over 120,000 characters in the complete table.
Unicode is not a Binary Encoding Scheme
Because Unicode is not itself a binary encoding scheme, just a list of characters, that brings the obvious follow-up question: how do we represent Unicode in binary, then?
And the answer: there are lots of different schemes! UCS-2, UTF-32, UTF-16, UTF-1, UTF-8, UTF-7, UTF-EBCDIC, there are many, many standards for representing Unicode characters in binary, most of them with various clever tricks to keep their size under control.
It's hard, especially because Unicode is an giant, unbounded table. New characters are being added to Unicode all the time.
If we're not interested in efficiency at all, we can just set aside 32 bits for each character. So long as Unicode stays less than 4 billion characters, this should work fine. This is known as UTF-32 , and it's very simple and easy to understand. It also wastes a lot of space. If UTF-32 were common, it would quadruple the size of most web requests.
Just Use UTF-8
The sneaky trick is that, as much as we sometimes need special characters, most of our day-to-day communication and code come out of the 128 characters that we originally used for ASCII.
UTF-8 is a scheme that uses 8-bytes for most characters, but uses extra bytes when necessary to encode special characters.
This means that UTF-8 is as efficient as latin-1 most of the time, while also being able to represent the entirety of Unicode.
Here's ñello, world ಠ_ಠ in
UTF-8:
11000011 10110001 ñ
01100101 e
01101100 l
01101100 l
01101111 o
00101100 ,
00100000
01110111 w
01101111 o
01110010 r
01101100 l
01100100 d
00100000
11100000 10110010 10100000 ಠ
01011111 _
11100000 10110010 10100000 ಠ
Just like latin-1, all of the ASCII characters look the same that they did in ASCII. It's not until we get into special characters that we see more bits start to appear.
UTF-8 is slowly consuming the entire internet — if we ask anybody what character encoding to use today, they'll probably say "just use UTF-8".
HTML
Okay, so, now that we know about hypertext, markup languages, and character encodings, let's look at the Hypertext Markup Language.
I think the best way to start, here, might be to start by looking at a completely empty HTML page.
Okay, that's not funny. Let's put some stuff in there.
<!DOCTYPE html>
<html>
</html>
So, this document doesn't contain anything except for a Doctype and an HTML element.
Creating a HTML Page
To get started, we need a file to work on. Which is very easy. Just open a file, anywhere
on your system, with a text editor, and name it sample.html. Now we can
open this file with a browser and it's an empty webpage. Easy peasy.
Doctype
HTML has many versions at this point — HTML5, HTML 4.1, XHTML 2.0 — and in order for the browser to render the HTML properly, it needs to know which version of HTML it is looking at.
Until HTML5, HTML was technically a subset of a language called SGML, and SGML required that documents come with a "Document Type Definition" which would lay out all of the rules for displaying the document. Any HTML document released before HTML5, then, would have a doctype that looks like:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
HTML5 dropped
SGML compatibility,
so it doesn't have to follow these rules anymore.
It was decided that, after the change, the doctype wouldn't need
a link to a document type definition any longer. Now it's just <!DOCTYPE html>.
All HTML5
documents start this way, to let browsers know that this is an
HTML5 document.
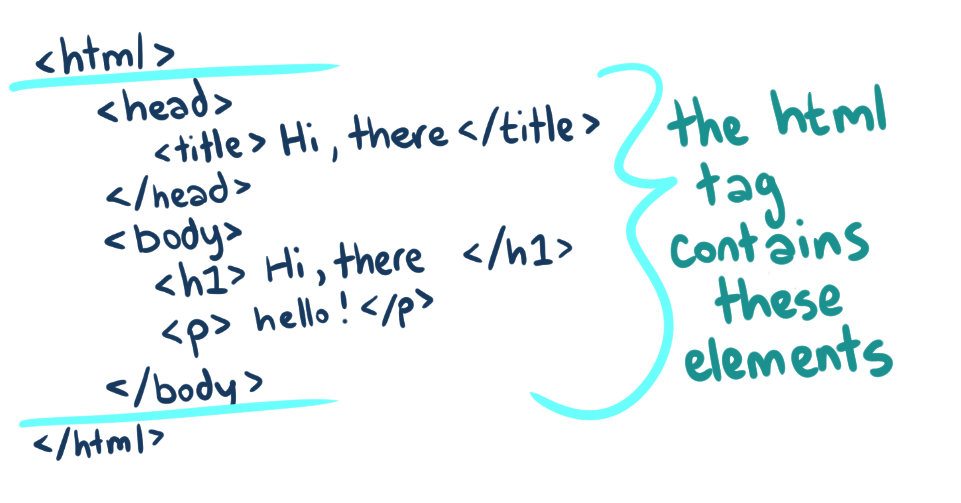
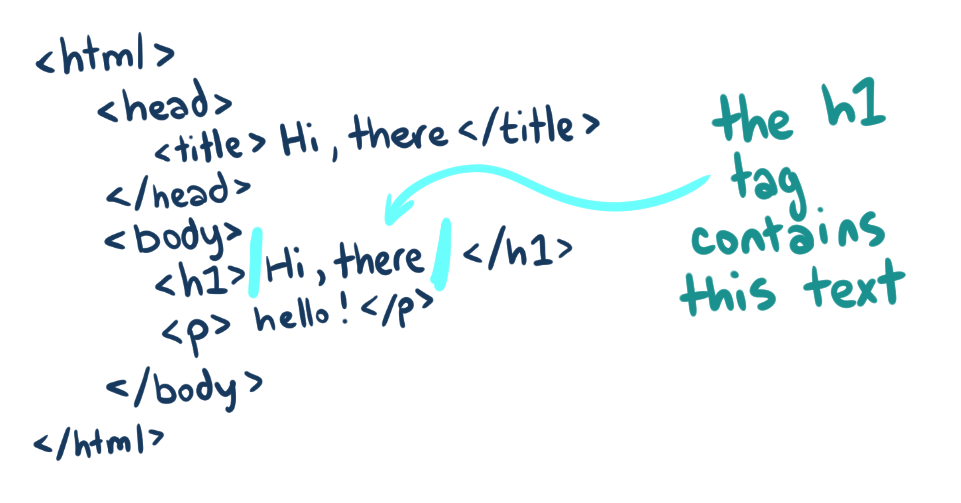
HTML Element
HTML is strictly hierarchical,
which means that every element in the document
must be enclosed by another element, except for the "root" element which
wraps everything in the entire document. This is the <html> element,
the outermost element that contains everything else.
HTML elements usually start with an
opening tag and end with a closing tag —
in this case, <html> is the opening tag and
</html> is the closing tag. Everything inside the <html> tag
is considered to be inside the document. Everything outside the <html> tag
is ... outside the document?
Attributes
<!DOCTYPE html>
<html lang="en">
</html>
HTML
elements can also have attributes, which are attached to the
opening tag and look like attribute="value".
In this case, we've attached the lang="en" attribute to the base HTML
element to let the world know that this HTML document is in English.
HTML Comments
<!-- Nobody can see this, no matter where you put it in the HTML -->
<!-- Comments are important in any language, even HTML -->
<!--
Comments
can
span
multiple
lines
-->
<!-- Sometimes you want to say stuff that nobody can see in the final page output. -->
<!-- Watch out, though - people can still see the comments in your HTML source. -->
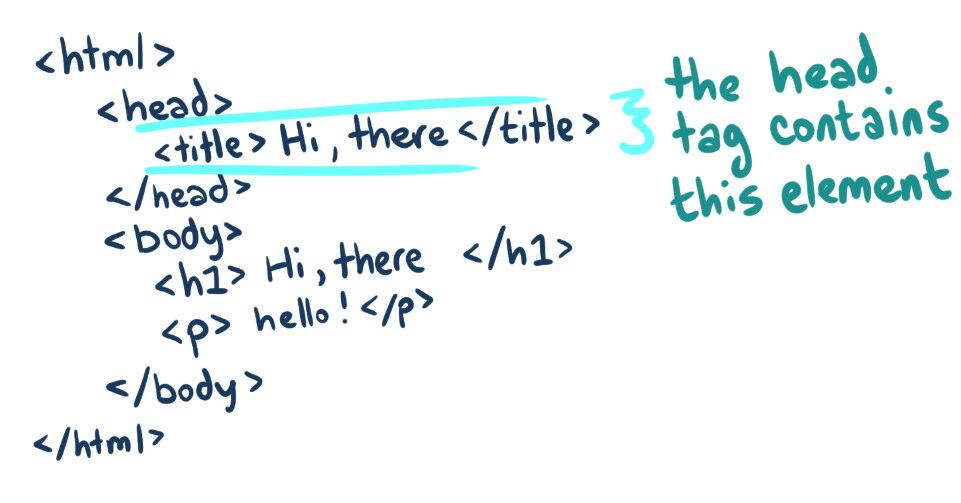
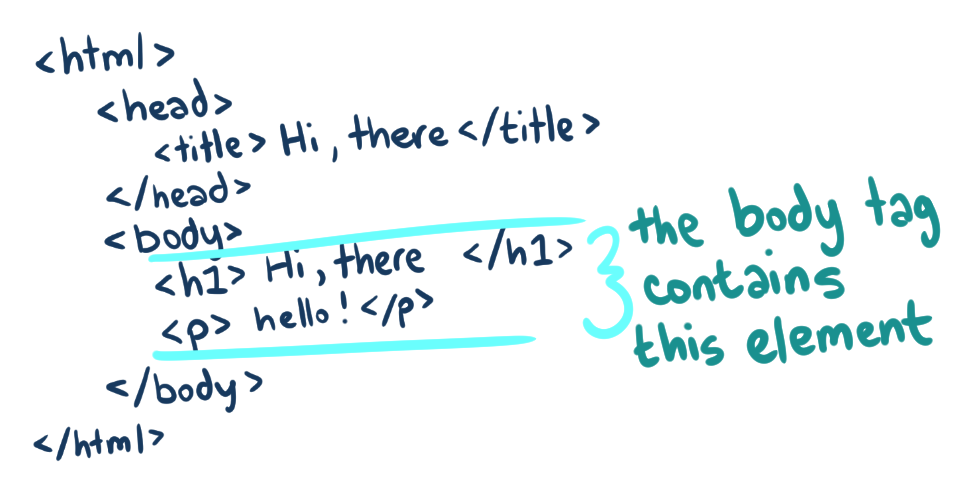
Head & Body
<!DOCTYPE html>
<html lang="en">
<head>
</head>
<body>
</body>
</html>
Inside the HTML element comes two key elements that divide the document into "the part you see" (the body) and "the part you don't see" (the head).
The head element is loaded before the rest of the page. It contains metadata about the content in the body like the document's title, as well as any style information that the page needs to load.
Elements What Go In The Head
The elements that go in the <head> element are
important metadata about the page.
It's possible to completely skip the head and go right on
to the body.
We shouldn't, though — a lot of stuff in the head is
important to the proper operation of the page.
Charset
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
</head>
<body>
</body>
</html>
This next part we've added, <meta charset="UTF-8"/>,
defines the character encoding of the document as
UTF-8.
The HTTP server that serves this document reads this when it serves the document and uses it to accurately report what binary encoding scheme this document is using.
The <meta> tag is a special tag that doesn't wrap any content, so it
doesn't require a closing tag.
Title
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Definitely Wikipedia</title>
</head>
<body>
</body>
</html>
The <title> element contains the title of the document.
In this case, it is Definitely Wikipedia.
Hey, it's a thing that we can see! Look at that sweet title.
Author & Description
<meta name="description" content="This is a description of the content on the page" />
<meta name="author" content="Andrea Authorface" />
The description meta tag is picked up by Google and Twitter when we share a link
to our html page somewhere.

The content of the description meta tag shows up here.
Best I can tell, the author meta tag isn't used anywhere and is completely optional.
Favicon
This is one of my favourite HTML tricks!
Let's take a look at my browser's tabs.

It almost seems like the icon is more important than the title, for most of these!
Also, and this is a fun thing to note, the Google Calendar favicon is accurate to the day that I'm looking at it which is a very cool touch.
These icons are called "favicons".
It's possible to link a favicon to our page by including a link to a very small image file.
A basic favicon link looks like this:
<link rel="shortcut icon" href="http://buildatheweb.cube-drone.com/favicon.ico" type="image/x-icon">
The type option here needs to match the type of the file that we're
linking to. In the case of an .ico file, it's image/x-icon,
but if we were to provide a .png file, it would be
image/png. This format is a standard called
MIME Type, and a list
of file-extension to
MIME Type mappings
can be found
here.
It's possible to really go to town optimizing our favicons — providing different
icon sizes and formats for every device that could possibly display our webpage,
but just a 32x32 .png file should be a serviceable option.
Style & Scripts
We're not going to talk about these yet! Wait until we get to our chapters on CSS and JavaScript respectively.
Body Elements
All of the parts of the document we've built so far? They're hiding just under the surface of our document. Now we look at the exciting parts that people can actually see!
Paragraphs
Let's start by just dropping a bundle of Charles Stross quotes in the <body>:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Definitely Wikipedia</title>
<meta name="description" content="This is a description of the content on the page" />
<meta name="author" content="Andrea Authorface" />
<link rel="shortcut icon" href="http://buildatheweb.cube-drone.com/favicon.ico" type="image/x-icon">
</head>
<body>
Like the famous mad philosopher said, when you stare into the void, the void stares also;
but if you cast into the void, you get a type conversion error.
(Which just goes to show Nietzsche wasn't a C++ programmer.)
Helpfiles are traditionally outnumbered by no-help files, which superficially resemble a helpfile
in form but not in content because they don't actually tell you anything you don't already know,
or they answer every question except the one you're asking, or you open them and a giant
animated paper clip leaps out and cheerfully asks where you want to go today. And wikis are worse.
</body>
</html>
When we open this HTML file in a browser, we get something that looks like this:
We wanted those paragraphs to be separate! The HTML just up and ignored our helpful spacing in the HTML file.
What we need is to indicate that those words are in separate paragraphs.
We can do this with the <p> tag.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Definitely Wikipedia</title>
<meta name="description" content="This is a description of the content on the page" />
<meta name="author" content="Andrea Authorface" />
<link rel="shortcut icon" href="http://buildatheweb.cube-drone.com/favicon.ico" type="image/x-icon">
</head>
<body>
<p>
Like the famous mad philosopher said, when you stare into the void, the void stares also;
but if you cast into the void, you get a type conversion error.
(Which just goes to show Nietzsche wasn't a C++ programmer.)
</p>
<p>
Helpfiles are traditionally outnumbered by no-help files, which superficially resemble a helpfile
in form but not in content because they don't actually tell you anything you don't already know,
or they answer every question except the one you're asking, or you open them and a giant
animated paper clip leaps out and cheerfully asks where you want to go today. And wikis are worse.
</p>
</body>
</html>
There we go.
Is The Indentation Really Necessary?
As we discovered just now, the whitespace in our HTML file doesn't matter.
So the indentation is just there to make the source code easier to read — it doesn't have any effect on the rendering of the page.
Headers
You've been reading this document (presumably), so you've noticed that it's divided into segments, by Headers, like the one that says "Headers" that I used to open this segment.
Headers come in six different "levels", from
<h1>
all the way up to
<h6>.
Conventionally,
<h1>,
the largest header, is used for the document's title.
<h2> is used for headings,
<h3> for sub-headings, and so on,
through the document.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Definitely Wikipedia</title>
<meta name="description" content="This is a description of the content on the page" />
<meta name="author" content="Andrea Authorface" />
<link rel="shortcut icon" href="http://buildatheweb.cube-drone.com/favicon.ico" type="image/x-icon">
</head>
<body>
<h1>Header Level One</h1>
<p>
There is a philosophy by which many people live their lives,
and it is this: life is a shit sandwich, but the more bread you've got,
the less shit you have to eat.
</p>
<h2>Header Level Two</h2>
<p>
These people are often selfish brats as kids, and they don't get better
with age: think of the shifty-eyed smarmy asshole from the sixth form
who grow up to be a merchant banker, or an estate agent, or one of the
Conservative Party funny-handshake mine's a Rolex brigade.
</p>
<h3>Header Level Three</h3>
<p>
(This isn't to say that all estate agents, or merchant bankers, or conservatives
are selfish, but that these are ways of life that provide opportunities
of a certain disposition to enrich themselves at the expense of others. Bear with me.)
</p>
<h4>Header Level Four</h4>
<p>
There is another philosophy by which people live their lives,
and it goes thus: You will do as I say or I will hurt you.
</p>
<h5>Header Level Five</h5>
<p>
Let me draw you a Venn diagram with two circles on it, denoting sets of individuals.
They overlap: the greedy ones and the authoritarian ones.
Let's shade in the intersecting area in a different color and label it: dangerous.
</p>
<h6>Header Level Six</h6>
<p>
Greed isn't automatically dangerous on its own, and petty authoritarians aren't
usually dangerous outside their immediate vicinity — but when you combine the two,
you get gangsters and dictators and hate-spewing preachers.
</p>
</body>
</html>
Lists
Lists can either be numbered or simply bulleted, and they can also contain sub-lists.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Definitely Wikipedia</title>
<meta name="description" content="This is a recipe for sausages on a bun" />
<meta name="author" content="Andrea Authorface" />
<link rel="shortcut icon" href="http://buildatheweb.cube-drone.com/favicon.ico" type="image/x-icon">
</head>
<body>
<h1> Tasty Sausage Recipe </h1>
<h2> Ingredients </h2>
<!-- ul stands for 'unordered list' -->
<ul>
<!-- li stands for 'list item' -->
<li>Sausages (Bratwurst or Italian Sausage)</li>
<li>Onions</li>
<li>Beer</li>
<li>Sausage Bun</li>
<li>Pickle Relish</li>
<li>Mustard</li>
</ul>
<h2> Instructions </h2>
<!-- ol stands for 'ordered list' -->
<ol>
<li>
Put the sausages and onions in a pan with a few cups full of water or beer
and crank the heat unil the liquid starts to boil.
</li>
<li>
Turn the temperature down and cover the pan with a lid. Let the
sausages and onions steam for 10 minutes.
</li>
<li>
Remove the lid, set aside the onions, and turn the heat up to medium-high,
browning the exterior of the sausages.
<em>A safe internal temperature for sausages is 165℃ </em>
</li>
<li>
<!-- it's possible to put lists inside of lists -->
Serve on a toasted sausage bun with
<ul>
<li>the onions</li>
<li>a chunky pickle relish</li>
<li>grainy mustard</li>
</ul>
</li>
</ol>
</body>
</html>
So Boring. Dying.
Do we really have to go over every single HTML tag?
Yes. Yes we do.
It's important. Every webpage is built out of this stuff.
These Basic HTML Sites Look Nothing Like Real Websites
We're going to get to that, soon! HTML is only part of the whole story, here — in order to look good, we also need CSS files to apply style and pizzazz to our page.
This is what the New York Times looks like without style:
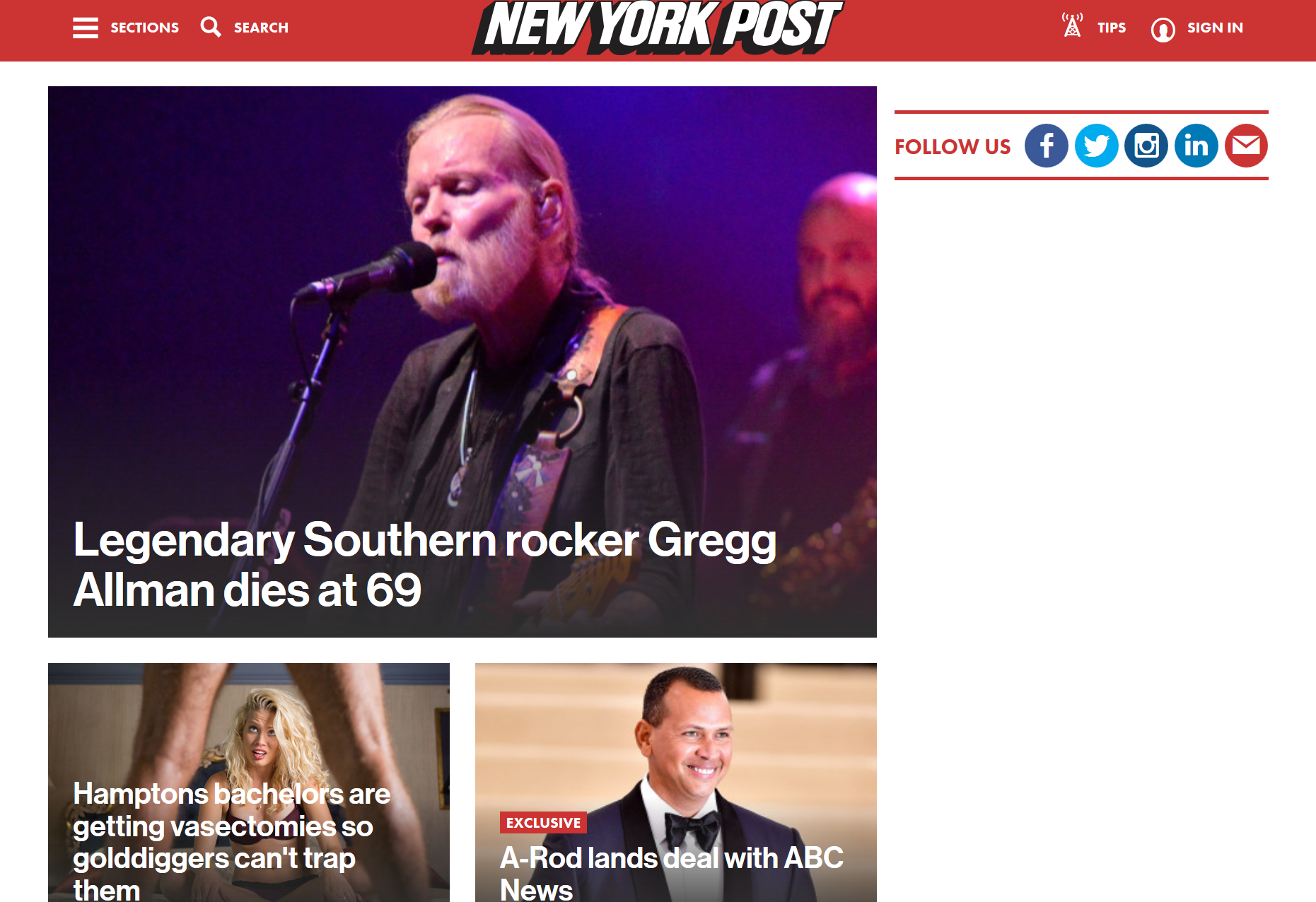
Okay, that was a cheap shot. I mean, this is what the New York Times looks like without a CSS stylesheet:
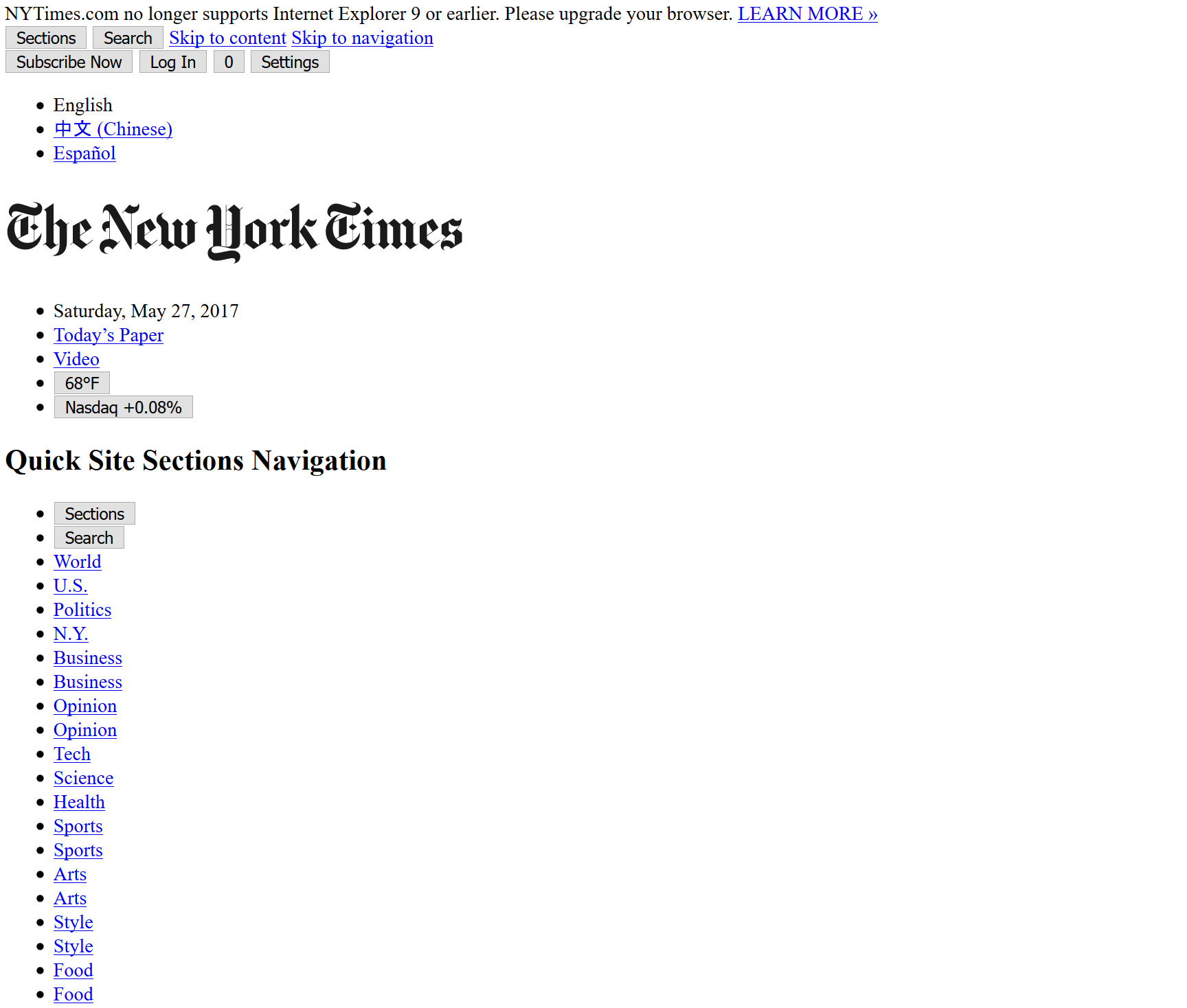
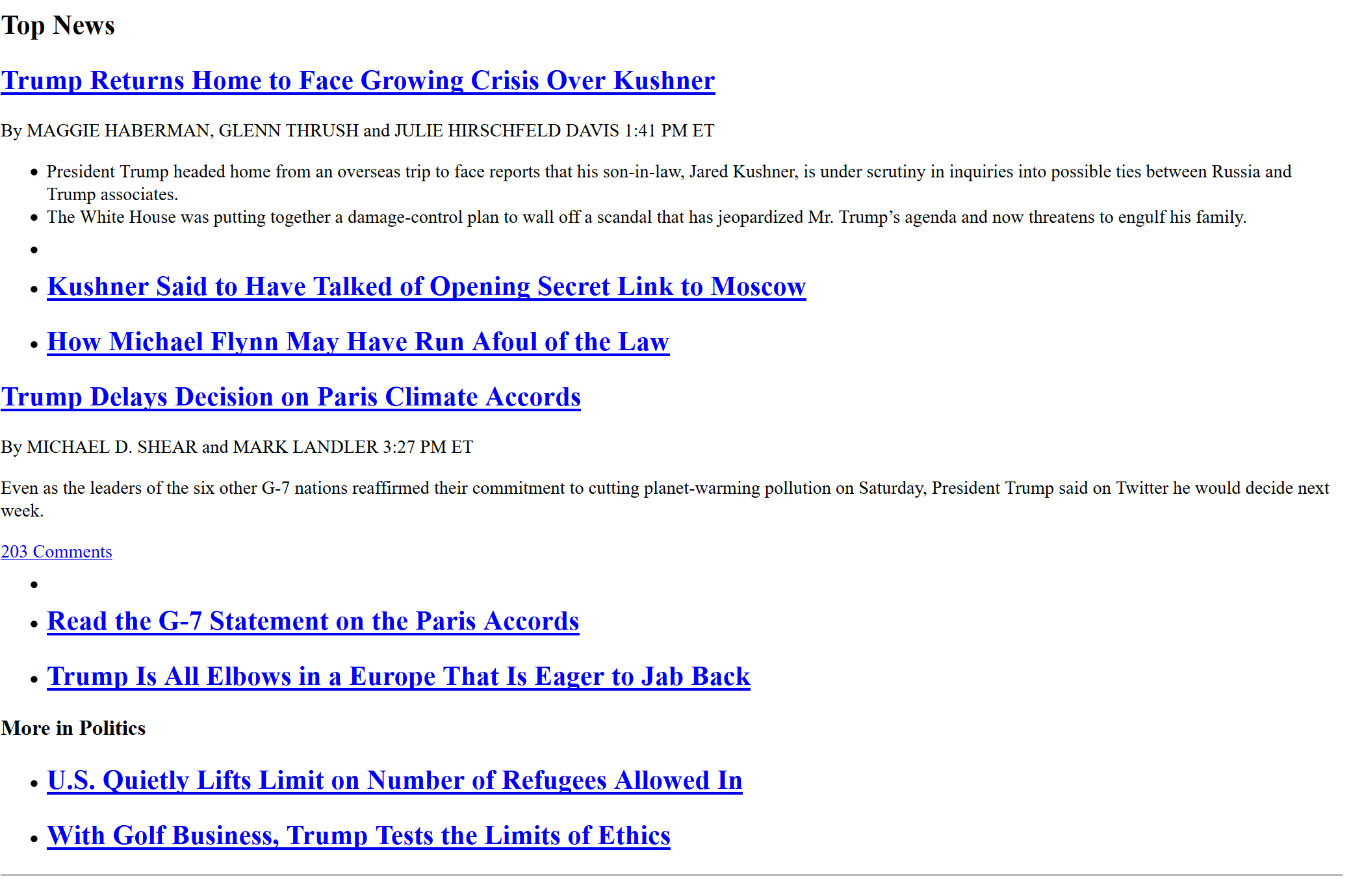
That's not much, right? Now let's look at what it looks like with a stylesheet:
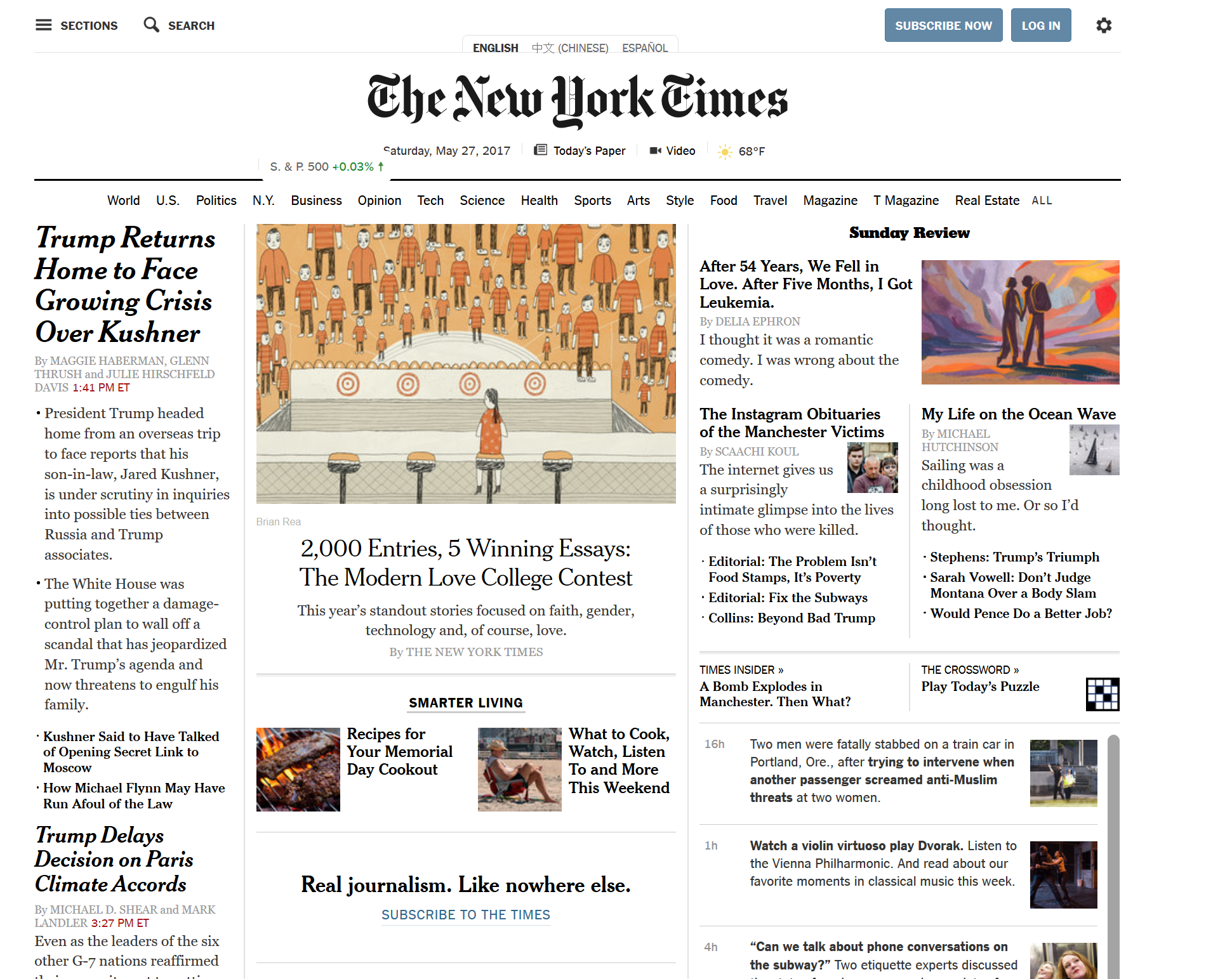
Wow! Much classier! We're going to be covering CSS in our next chapter, but we need to understand vanilla HTML first!
One of the rules of good web design is that the HTML of a page should be as clean to read without CSS as it is with it — some users, especially the visually impaired, use the raw HTML of a page without any additional style.
Tables
Sometimes we need to display a table of data. Tables have rows, columns, and headers.
<table>
<tr> <!-- tr means "table row" -->
<th>Vegetable</th> <!-- th means "table header" -->
<th>Fries</th>
<th>Chips</th>
<th>Smoothies</th>
<th>Real</th>
</tr>
<tr>
<td>Potato</td> <!-- td means "table data" -->
<td>Yes</td>
<td>Yes</td>
<td>No</td>
<td>Yes</td>
</tr>
<tr>
<td>Carrot</td>
<td>No</td>
<td>No</td>
<td>Yes</td>
<td>Yes</td>
</tr>
<tr>
<td>Beet</td>
<td>No</td>
<td>Yes</td>
<td>Yes</td>
<td>Yes</td>
</tr>
<tr>
<td>Brotato</td>
<td>Yes</td>
<td>Yes</td>
<td>Yes</td>
<td>No</td>
</tr>
</table>
Tables are pretty flexible about how you align them, but
td and th elements always go
inside tr elements.
<table>
<tr>
<th>Name:</th>
<td>Curtis</th>
</tr>
<tr>
<th>Class:</th>
<td>Software Developer</th>
</tr>
<tr>
<th>Blood Type:</th>
<td>Double Plus Good</th>
</tr>
<tr>
<th>Sandwich:</th>
<td>BLT</th>
</tr>
<tr>
<th>Weaknesses:</th>
<td>Myriad</td>
</tr>
</table>
Special Characters
Certain characters, like & and >,
are used in HTML
markup.
We cannot simply type the < character into our
HTML —
the browser would confuse it for the start of an
HTML tag.
Instead, we need to use a special escaping syntax: HTML Entities.
The ampersand character, &, can be
represented with &.
The "greater than" character, >, can
be represented with >.
The "less than" character, <, can
be represented with <.
With these three entities, we can represent any
HTML characters
that we come across.
Special characters can represent more than just
HTML characters,
though! There are many special typographic characters that
just don't exist on the keyboard, like "—" (—),
"©" (©), and "€" (€).
On top of that, if we don't want to enter Unicode characters, we
can always reference them directly by their Unicode code point, like
"❤" (❤), "ൠ" (ൠ)
or "🤘"(🤘).
Emphasis and Strong
This one's going to be really quick. Sometimes, you want to emphasize text or really, really emphasize text.
This is where the <em> (for emphasis) and <strong> (for strong emphasis) tags shine.
Figure them out on your own time. I'm not yer' daddy.
Links
Do you know what would make a lot of sense? If the
HTML tag for
links between pages was <link>.
But <link> was already taken, so instead,
a link to another page is represented with the
<a> tag. Which stands for anchor.
So, if we wanted to construct a link to, say,
a video
about the death of Flash from the point of view of some
characters who were animated in Flash, I'd need to use an
<a> tag, like so:
<a href="https://www.youtube.com/watch?v=L0nuQ5o2DYU"> a video about the
death of Flash from the point of view of some
characters who were animated in Flash </a>
Yeah, that's right, the URL
is encoded in an attribute called href.
This whole deal is just a cascade of nonsense. It's possible to
connect all of these details with minutiae in the history of
HTML, but I think
it's easier just to remember "links are a href=" without
trying to justify it.
Absolute vs. Relative Links
There are two different ways to link to content. These linking rules apply to anything that we might link to — other web pages, images, videos, stylesheets — the rules are the same for all of them.
An absolute link is a full URL, like the one that we saw in the first chapter, with protocol, domain, and path.
One of these:
http://buildatheweb.cube-drone.com/images/chapter3/hot_dog.jpg
As we've established, this refers to /images/chapter3/hot_dog.jpg
on the domain buildatheweb.cube-drone.com using the http protocol.
A relative link is a link that contains less information, and depends on context to resolve the full URL. The rules of resolving relative links can be a little bit complicated, but it's almost always a better idea to use relative links rather than absolute ones when we are building webpages, because if we leave information like the domain name and protocol out of our links, we can change these things more easily.
This is particularly useful because when we are developing our web sites, we usually do not have a domain name, yet. Even if we do, it's common practice to develop our site on our personal computer, without a domain name, before launching it to our production server, where it does have a domain name — so, relative links are important.
The first rule of relative links is that they always resolve to
the same domain as the source page. I cannot, for example,
create a relative link to a youtube.com page
from buildatheweb.cube-drone.com.
That means, though, that if we wanted to link to /images/chapter3/hot_dog.jpg,
but we know that this file is going to be on the same
domain and protocol as the place that we are linking from,
we can just leave out the domain and protocol entirely,
and include a link to /images/chapter3/hot_dog.jpg.
<!-- these links go to the same place -->
<a href='http://buildatheweb.cube-drone.com/images/chapter3/hot_dog.jpg'>Hot Dog</a>
<a href='/images/chapter3/hot_dog.jpg'>Hot Dog</a>
The / at the beginning of the relative link communicates
the web root — in the case of this page, the web root is
buildatheweb.cube-drone.com/.
If we leave out the web root (represented by the initial / character)
we instead ask the web server to construct the link
starting at the folder that we are currently in.
Which means that, because we are already at the web root,
we could link to images/chapter3/hot_dog.jpg
and it, again, would refer to the same file.
<!-- these links go to the same place -->
<a href='http://buildatheweb.cube-drone.com/images/chapter3/hot_dog.jpg'>Hot Dog</a>
<a href='/images/chapter3/hot_dog.jpg'>Hot Dog</a>
<a href='images/chapter3/hot_dog.jpg'>Hot Dog</a>
However, let's now imagine that our
HTML file is located
in the /images directory.
The first two links would stay the same — the absolute link
and the relative link that references the web root — but
the relative link that didn't start with /
would no longer be rooted at the same
directory. It would become invalid.
<!-- these links go to the same place -->
<a href='http://buildatheweb.cube-drone.com/images/chapter3/hot_dog.jpg'>Hot Dog</a>
<a href='/images/chapter3/hot_dog.jpg'>Hot Dog</a>
<!-- because we are already in the images directory,
this link would go to the wrong place: /images/images/chapter3/hot_dog.jpg -->
<a href='images/chapter3/hot_dog.jpg'>Hot Dog</a>
<!-- this would fix the problem -->
<a href='chapter3/hot_dog.jpg'>Hot Dog</a>
Images
Links are all well and good, but let's get our hands dirty with some honest-to-goodness multimedia content. Images!
Images can be rendered with the <img> tag, which works a lot like the
<a> tag, but with src instead of href.
<!-- images work like links but use 'src' instead of 'href' -->
<img src='http://buildatheweb.cube-drone.com/images/chapter3/hot_dog.jpg'>
<img src='/images/chapter3/hot_dog.jpg'>
<img src='images/chapter3/hot_dog.jpg'>
Pictured: A Picture

The title attribute can be used to provide pop-over text for an image.
The alt attribute should be used to provide screen-reader text for an image,
to help the visually impaired.
<img src="images/chapter3/hot_dog.jpg"
alt="A picture of a hot dog"
title="Do I look like I know what a JPEG is? I just want a picture of a god-dang hot dog.">
Pictured: A Picture With Pop-Over Text and Alt Text
Divisions, Sections, and Asides
We're not really going to talk about divisions and sections until we get to the chapter on CSS.
For now, I'm just going to say that the div, section,
nav, and aside tags are all invisible tags that we wrap around
other content.
"Why even bother with invisible tags?" — well, they're useful for grouping content together for styling!
They're important, but they're not really visible until we start to style things.
Audio & Video
It's possible to embed both audio and video content in the browser. This is a relatively new feature.
Let's look at some!
<audio controls>
<source src="horse.ogg" type="audio/ogg">
<source src="horse.mp3" type="audio/mpeg">
Your browser does not support the audio element.
</audio>
<video width="320" height="240" controls>
<source src="movie.mp4" type="video/mp4">
<source src="movie.webm" type="video/webm">
Your browser does not support the video tag.
</video>
The audio and video tags work a little bit differently
than the img tag. Instead of having just one src attribute,
these tags wrap multiple source tags that each have their own src
attribute.
The reason for this is that the browser can cycle through the various sources until
it finds a source type that it supports — not all browsers support all of the different
audio and video types.
If a browser is too old to understand
the audio or video tag, it will just display the text
contained within the tag: "Your browser does not support the video tag".
Like with images, there are lots of different potential file formats for both audio and video files — although mostly we just need to remember to use mp3 for audio and mp4 for video if we want every browser to be able to play our files.
iFrames
The frame tag was once a tag that allowed for webpages to be constructed
out of parts of other pages.
Frames aren't a thing anymore, though. They're no longer part of the HTML specification. Frames are dead.
What remains is the concept of the <iframe> — the inline frame.
It allows for a webpage to be embedded within a webpage. We've been looking at them every time I've embedded a sample webpage into this one!
<!-- this is the iframe-->
<iframe src="ex10.html"> </iframe>
<!-- this is the code that's inside the iframe-->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>iFrame Example</title>
<meta name="description" content="ifraaaaaame">
</head>
<body>
<h3>This is an iFrame</h3>
<p>It's an entirely different webpage, but it exists inline on this webpage. </p>
</body>
</html>
Many More Tags
I feel like we've covered enough HTML
tags that we can get a good start on building a webpage,
but there are lots of other tags, like abbr, form, and input
that we'll have to touch on in later chapters.
HTML Validation
How do we know if we've built our HTML page correctly? There are so many rules and we don't even know half of them yet.
One helpful way to know if we've built our websites properly is to run them through a validator, which will check our HTML for common errors. This one, from the W3C, is a good choice.
Here's the validation report for this site. If I've done my job, this should be completely empty, although I can guarantee you that it is probably not.
Let's Put it All Together
We've learned a lot of stuff, put some tags together, but now, I think it's time to put together a HTML curriculum vitae for my friend, Dr. Frampton Q. Fakenamington.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Dr. Frampton Q. Fakenamington</title>
<meta name="description" content="You should hire him, he is pretty great.">
</head>
<body>
<h1>Dr. Frampton Q. Fakenamington</h1>
<img src="images/chapter3/professor.jpg">
<p>
<a href="mailto:frampton@sample.org">frampton@sample.org</a>
</p>
<p>
<a href="tel:+16045555555">604-555-5555</a>
</p>
<p>
<address>
123 Fake St.
Surrey, BC, Canada
V1V 1V1
</address>
</p>
<h2>Professional Skills</h2>
<ul>
<li>Doctoring, but not the medical kind, the kind where mostly you write grant proposals</li>
<li>Office (Word/Excel/PowerPoint)</li>
<li>Some Kung-Fu</li>
<li>Attentoin to Detail</li>
</ul>
<h2>Education</h2>
<h3>Learnington University</h3>
<p> Surrey, B.C. </p>
<p> 2000-2017 </p>
<p> PhD, Theoretical Mustard Sciences </p>
<p>
For the past 17 years, I've been advancing the field of theoretical mustard sciences, mostly
by consuming a variety of delicious mustards. All of my results are published in the
New England Journal of Various Mustards, a journal that I am the sole contributor and editor for.
</p>
<h3>Publications</h3>
<table>
<thead>
<tr>
<th>Title</th>
<th>Authors</th>
<th>Journal</th>
<th>Date</th>
</tr>
</thead>
<tbody>
<tr>
<td>A Simple Taxonomy Of Grainy Mustards</td>
<td>Frampton Fakenamington</td>
<td>New England Journal of Various Mustards</td>
<td>2016</td>
</tr>
<tr>
<td>Ballpark or Dijon: The Controversy Rages</td>
<td>Frampton Fakenamington, Hurgen Jurgen</td>
<td>New England Journal of Various Mustards</td>
<td>2015</td>
</tr>
</tbody>
</table>
<h2>Interests</h2>
<ul>
<li>Mustard</li>
</ul>
<h2>Class Schedules</h2>
<p>
For any students looking for the syllabus for
<strong>IAT 208 — Introduction to Hot & Spirit Mustards </strong>,
you can find it
<a href="http://www.seriouseats.com/2014/05/mustard-manual-guide-different-types-mustard-varieties-dijon-brown-spicy-yellow-hot-whole-grain.html">here</a>.
</p>
</body>
</html>
This produces the final product:
Good ol' Dr. Fakenamington now has a website that would look at home in any modern CS department.
Use Developer Tools to Take a Look Under The Hood
Do we want to see that HTML that sits underneath our favourite websites? Even this website? Yes. Yes we do.
Every modern browser now includes an "Inspect Element" or Developer Tools option.
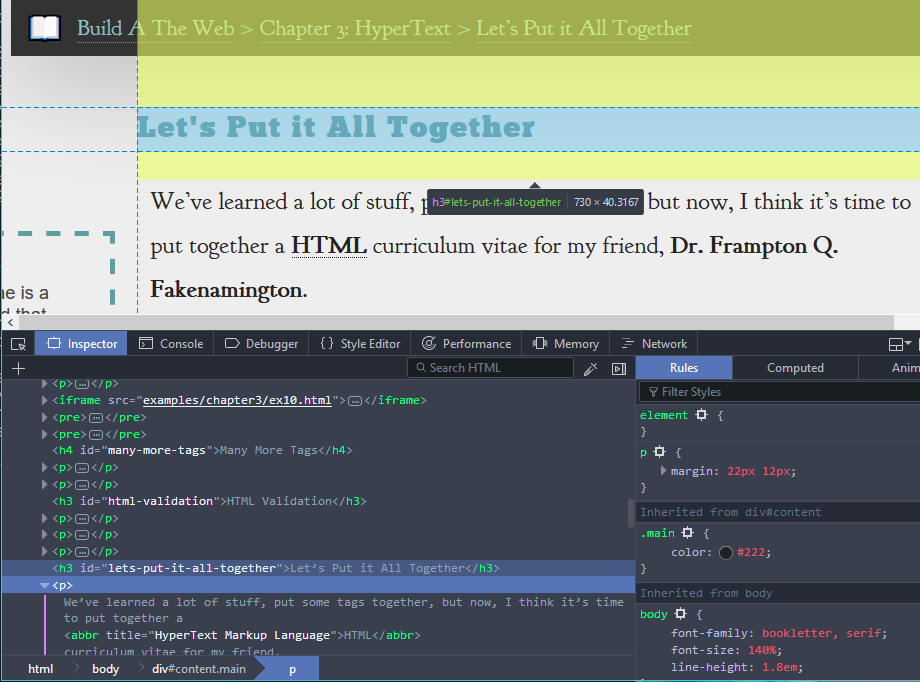
We can look at all of the HTML that comprises any page that we visit.
It's also possible to use the HTML editor to change any page that we want to, to read whatever we like. As it turns out, this is great fun.
The Developer Tools are a Swiss Army Knife of useful tools and techniques for doing Web Things, and we'll be returning to them frequently for sweet tricks and tips.
Chapter 2 Summary
In this chapter, we've:
- Spent entirely too much time learning about Unicode and character encodings.
- Learned about markup languages in general, and HyperText Markup Language in specific.
- Created an HTML page, with a
- Learned about a whole whack of HTML tags, like
- Cracked open a page using developer tools
Chapter 2 Resources
Chapter 3: Cascading Style Sheets
It's all well and good to be able to author webpages, but we've come to expect a little more graphical acuity from the modern internet. A little more punch. A little more pizzazz. A touch more razzamatazz.
The CSS language is all about styling things.
The Content Stays the Same
One of the foundational rules of CSS design is that the content should be laid out in a way that makes styling it easy, but also that the content should be laid out in such a way that the theme could completely change without touching the HTML at all.
The site CSS Zen Garden has the exact same content rendered a few hundred different ways, using nothing but a succession of different stylesheets.
CSS is Made of Many Small Rules
CSS is composed of many small rules, each responsible for the display rules controlling a handful of elements.
A CSS rule is composed of two parts: the selector and properties.
The selector is a part of the CSS rule that defines which HTML tags we are interested in targeting — for example, all header tags or just the h1 tag or paragraph text.
The properties are a set of rules that define how to display the object — for example, should be blue or should be really big.
Including CSS In Our Page
So, let's create a CSS rule that
defines that just the h1 tag should be really blue and really big.
h1 {
color: blue;
font-size: 300%;
}
Here, the h1 is the selector, and everything between the curly braces are the properties.
Let's add this rule to our HTML file and watch it in action.
We can do this with the <style> tag.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>CSS Example</title>
<meta name="description" content="CSS">
<style>
h1{
color: blue;
font-size: 300%;
}
</style>
</head>
<body>
<h1> Hello, world. </h1>
<p> Well would you look at that? That h1 element is big and blue! </p>
</body>
</html>
Success! We've applied color:blue; and font-size:300% to the h1 tag!
There are three ways to apply CSS styles to our pages:
- By including it within the
styletag, which we've just seen - By attaching a CSS file to the page
-
By attaching CSS properties directly
to an HTML element using the
styleattribute.
CSS File
If we have a lot of style to define — and we probably do — we can keep all of these style
definitions in a separate .css file.
<link rel="stylesheet" type="text/css" href="style.css">
Here, we link to the style.css file. Any CSS
rules that we write in this file will be applied to this page.
Our style.css file might contain this:
h1{
color: blue;
font-size: 300%;
}
Success once more!
Directly Applying CSS Properties
Finally, it's possible to apply CSS
properties directly to HTML elements
using the style property.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>CSS Example</title>
<meta name="description" content="CSS">
</head>
<body>
<h1 style="color:blue; font-size:300%;"> Hello, world. </h1>
<p> Well would you look at that? That h1 element is big and blue! </p>
</body>
</html>
When we do this, we don't need to bother with selectors — we've already got the element that we want to apply this rule to, right here!
Success once again! Any way we apply these styles to the HTML, the result is always the same.
Selectors
The selector is a part of the CSS rule that defines which HTML tags we are interested in targeting — so let's dig in a bit and learn how to select elements.
Classes & IDs
Sometimes, we want to be able to select a very specific HTML tag, or a specific group of tags, and simple selection rules just don't cut it.
Let's take a look at this code from Dr. Fakenamington's CV:
<p>
<a href="tel:+16045555555">604-555-5555</a>
</p>
This is very clearly a telephone number. We might want to apply a special style to just telephone numbers all across the page!
A class allows us to apply a style to a group of elements.
What we can do is mark it with the telephone class:
<p>
<a class="telephone" href="tel:+16045555555">604-555-5555</a>
</p>
Then, we can write a CSS rule that makes all telephone numbers bold.
Class selectors in CSS start with the . character.
.telephone{
font-weight: bold;
color: brown;
}
That should do it. It's also possible to apply more than one class to the same object!
<p>
<a class="telephone bigger" href="tel:+16045555555">604-555-5555</a>
</p>
<p>
<a class="telephone smaller" href="tel:+17785555555">778-555-5555</a>
</p>
.telephone{
font-weight: bold;
}
.bigger{
font-size: 120%;
}
.smaller{
font-size: 80%;
}
A class works for an object that might appear again and again on a page — like telephone numbers, or dates — but sometimes we want to identify a single, unique object. Let's imagine, for example, we had more than one telephone number, and we wanted to name them different things.
<p>
<a class="telephone" id="office_number" href="tel:+16045555555">604-555-5555</a>
</p>
<p>
<a class="telephone" id="cel_number" href="tel:+17785555555">778-555-5555</a>
</p>
We can select these identifiers using the # character.
.telephone{
font-weight: bold;
}
#office_number{
color: fuchsia;
}
#cel_number{
color: red;
}
Fragments
Why in the world would we ever use IDs? — It seems like everything an ID can do, a class can do better!
The ID serves a double purpose, though! It's also possible to link directly to an ID within a webpage. On this page, we can navigate directly to the paragraph on CSS Is Made of Many Small Rules by navigating to http://buildatheweb.cube-drone.com/#css-is-made-of-many-small-rules.
The reason that we can do this? The header element has the ID css-is-made-of-many-small-rules.
Children
In Chapter 3, we talked about how HTML is hierarchical — with every element enclosed by another element.
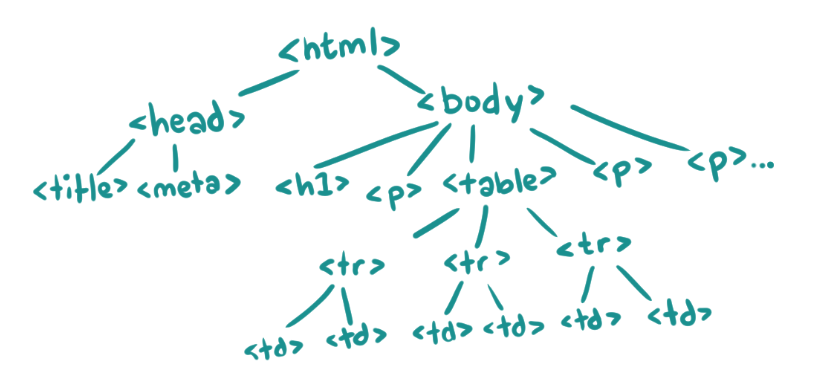
This means that we can think of our entire HTML document like a tree data structure.
There's a thicket of terminology we're going to borrow, then, from the world of tree-shaped data.
| Node | A single object within the tree. html is a node. tr is a node. |
|---|---|
| Root | The node at the base of the tree. In the case of HTML, this is always the html tag. |
| Child |
A node directly connected to another node, moving away from the root. In our diagram,
body is the child of html, and table is the
child of body.
|
| Descendant |
A node reachable by repeatedly moving from parent to child. In our diagram,
every node is a descendant of html, and table's
descendants are all of the tr and td elements.
|
| Parent |
A node directly connected to another node, moving towards the root. The opposite of a child.
In our diagram, the body is the parent of table, which is the parent
of tr.
|
| Ancestor |
A node reachable by repeatedly moving from child to parent. In our diagram,
body has only html as its ancestor, whereas
td has tr, table, body, and
then html.
|
| Leaf |
Nodes that do not have any children. In our diagram, title, meta,
h1, p, and td are all leaf nodes.
|
Now let's look at a new problem from Dr. Fakenamington's CV:
<tbody>
<tr id="a-simple-taxonomy-of-grainy-mustards" >
<td>A Simple Taxonomy Of Grainy Mustards</td>
<td>Frampton Fakenamington</td>
<td>New England Journal of Various Mustards</td>
<td>2016</td>
</tr>
<tr id="ballpark-or-dijon">
<td>Ballpark or Dijon: The Controversy Rages</td>
<td>Frampton Fakenamington, Hurgen Jurgen</td>
<td>New England Journal of Various Mustards</td>
<td>2015</td>
</tr>
</tbody>
Let's imagine that we want to apply a property to each of the td
elements in a-simple-taxonomy-of-grainy-mustards,
but not in ballpark-or-dijon.
If we tried to use the selector td, our property would be applied to both groups!
We could take what we've learned so far about classes, applying a taxonomy class to each child
of a-simple-taxonomy-of-grainy-mustards:
<tbody>
<tr id="a-simple-taxonomy-of-grainy-mustards" >
<td class="taxonomy">A Simple Taxonomy Of Grainy Mustards</td>
<td class="taxonomy">Frampton Fakenamington</td>
<td class="taxonomy">New England Journal of Various Mustards</td>
<td class="taxonomy">2016</td>
</tr>
<tr id="ballpark-or-dijon">
<td>Ballpark or Dijon: The Controversy Rages</td>
<td>Frampton Fakenamington, Hurgen Jurgen</td>
<td>New England Journal of Various Mustards</td>
<td>2015</td>
</tr>
</tbody>
But there's an easier way! Without creating the taxonomy class at all,
we can just select all td elements that are children of an element with
the ID a-simple-taxonomy-of-grainy-mustards.
We can do this by just writing one selector after the other:
#a-simple-taxonomy-of-grainy-mustards td{
font-weight: bold;
font-family: Verdana, sans-serif;
color: purple;
}
This selects all td elements that are children of #a-simple-taxonomy-of-grainy-mustards:
Wildcards
Let's imagine we want to select every element inside a table, or every element on the entire page, regardless of what type of element that it is.
The wildcard operator, *, selects... everything.
.table * {
font-weight: bold;
font-family: Verdana, serif;
}
* {
font-size: xx-large;
}
M-M-M-Multi-Selectors
Let's imagine that we have a rule that we want to apply to a group of different
selectors at the same time. We can do this by chaining together selectors
with a , character.
For example, we might want all of our header elements, all of our links, and all of our journal table entries to be a nice cool teal color.
h1, h2, h3, h4, h5, h6, a, .journal td {
color: teal;
}
Hover And Pseudo-Classes
Alongside the classes that we define, like telephone, the browser will add and remove
its own classes to
HTML elements. These automatic classes are called
"pseudo-classes".
For example, an a link will have the pseudo-class visited, when the
client has already visited that link. Any element will have the pseudo-class hover,
when the client's cursor is hanging over it.
The selector for pseudo-classes uses a : instead of a . — so,
a pseudo-class selector might look like this:
:hover{
background-color: pink;
}
That's good, but that CSS rule will apply that
hover property to anything on the entire page! We can glom the hover property on to any
other selector, though, by combining them: p:hover or .telephone:hover.
Let's look at an example:
<div class="big-ol-block">
<p>Put your mouse over this</p>
</div>
.big-ol-block{
width: 300px;
height: 200px;
background-color: blue;
}
.big-ol-block p{
color: white;
}
.big-ol-block:hover{
background-color: green;
width: 500px;
}
A Common Mistake With Pseudo Classes
Here's a mistake that I frequently make with these elements:
<div class="big-ol-block">
<p>Put your mouse over this</p>
</div>
.big-ol-block{
width: 300px;
height: 200px;
background-color: blue;
}
.big-ol-block p{
color: white;
}
.big-ol-block:hover{
background-color: green;
font-size: xx-large;
width: 500px;
}
.big-ol-block :hover{
background-color: red;
font-family: monospace;
}
Looking at this example, what's the difference between .big-ol-block:hover
and .big-ol-block :hover?
It's the space, right? .big-ol-block:hover selects the big-ol-block
class when hover is applied to it, but .big-ol-block :hover selects
any children of the big-ol-block class that the cursor is
hovering over — namely, the p element contained within.
With a Little Help From Our Friends
The selector library allows us to select all sorts of things on a webpage to apply different styles to them. We've talked about some of the features of selectors, but the best way to learn this topic, I think, is interactively.
So, check out this interactive CSS selector tutorial. It covers everything I've covered, and much more!
Properties
The other half of the CSS rule is the list of properties
that define what we want the selected element to look like, like font-family: Arial or color: blue.
Inheritance
When we set some CSS properties in a rule, they apply not just to an element, but to all children of that element.
For example, let's imagine that we want to change the font for the entire document at once. We could use the wildcard selector:
* {
font-family: "Courier New", monospace;
}
But if we just set the font for the body element, which wraps all content
on the page, all of the children of body will inherit that font.
body {
font-family: "Courier New", monospace;
}
That makes it clearer when we want to use a different font for a different part of the page.
body {
font-family: "Courier New", monospace;
}
h1, h2, h3, h4, h5, h6{
font-family: "Arial", sans-serif;
}
<h1>Hello, world</h1>
<p>
We're a lazy, inattentive chef, so a sous vide is probably
a better purchase than a pressure cooker.
</p>
<h2>Sous Vide</h2>
<p>
Sous vide is a cooking technique where we leave a
vacuum-sealed bag of our food in hot water for a long time.
It makes it really hard to overcook our food, because we
can forget it for hours and it doesn't matter.
</p>
Some CSS properties do not inherit. Others do. This definitely happens on a case-by-case basis, so the only way to really learn which ones are which are a little bit of trial and error — hopefully, with a bit of experience, this will become intuitive.
Inheritance Overwritten
An inherited property is always overwritten by an actual rule that sets the property. If, for example, we were to have:
body {
font-family: "Courier New", monospace;
}
p {
font-family: Arial, sans-serif;
}
In this case, the p element would inherit the font-family: "Courier New", monospace;
property from body — but immediately write over it with the font-family: Arial, sans-serif;
property of its own.
The Cascade
What happens when two different rules both select the same element and contain the same property? How do we resolve overlapping properties?
Well, the rules that define how overlapping properties collide are called the cascade, and they're the reason that CSS stands for "Cascading Stylesheets", rather than just "Stylesheets".
For each property applied to an element, the priority of that property is calculated based on its importance then specificity then order. Higher priority rules win out over lower priority rules, but the final set of properties that are applied to an element can be a combination of a set of properties from a variety of different CSS rules.
Importance
The first rule of the cascade is that you do not talk about the cascade.
The second rule of the cascade is that a property with the !important
tag always wins over a property that doesn't have an !important
tag.
p {
font-family: "Courier New", monospace;
color: blue !important;
font-size: small;
}
p {
font-family: Arial, sans-serif !important;
color: red;
font-size: medium;
}
p {
font-family: "Times New Roman", serif;
color: green;
font-size: large !important;
}
<p> This text should be large, blue, and in the Arial font </p>
Specificity
The next rule of the cascade is that more specific selectors always win out over less specific selectors.
- Properties applied directly to an HTML element have the highest specificity.
- An ID selector (
#this) is more specific than a class (.this) - A class is more specific than a type selector (
td) - Selectors that chain children together (
table tr td) are more specific than selectors that don't (td).
p {
font-family: "Courier New", monospace;
color: blue;
font-size: small;
}
/* an ID has the highest specificity */
#argle {
font-family: Arial, sans-serif;
color: red;
font-size: medium;
}
.bargle {
font-family: "Times New Roman", serif;
color: green;
font-size: x-large;
}
/* because it is part of a chain, p .bargle has higher specificity than just .bargle */
p .bargle {
font-family: Verdana, sans-serif;
color: pink;
font-size: xx-large;
}
<p id="argle" class="bargle"> This text should be medium-sized,
red, and in the Arial font </p>
<p class="bargle"> This text should be large, green,
and in the Times New Roman font </p>
<p> This text should be small, blue,
and Courier New </p>
<p> <span class="bargle"> This text should be extra large,
pink, and in the Verdana font </span></p>
Order
The final rule of the cascade is that, with all other things being equal, the last rule defined wins.
p {
font-family: "Courier New", monospace;
color: blue;
font-size: small;
}
p {
font-family: Arial, sans-serif;
color: red;
font-size: medium;
}
p {
font-family: "Times New Roman", serif;
color: green;
font-size: large;
}
<p> This text should be large, green, and in the Times New Roman font </p>
Web Typography
Fonts! They're a huge part of design and we're going to talk about them for a bit!
The typographic choices that we make surrounding our site's body text — the text that we display when we're not displaying anything else — set the design tone for the whole rest of the document, and the four choices that matter the most are:
- Font Choice
- Font Size
- Line Spacing
- Line Length
Font Choice & The Web Safe Fonts
We can choose a font for our website using the font-family property.
body {
font-family: Helvetica;
}
What do we do if our website visitor doesn't have
Helvetica installed on their computer?
The font-family property allows us to list a whole group of fonts. The browser will
try to use each one of these fonts in turn until it finds one that works.
body {
font-family: Helvetica, Arial, sans-serif;
}
While some fonts, like Arial,
Times New Roman,
Verdana,
Georgia,
Courier New,
Arial Black, and
Impact
exist on virtually every computer, the browser also provides default fallback fonts called
serif, sans-serif, monospace, cursive,
and fantasy.
It's best to include one of these at the end of every font-family declaration —
that way, even if our webpage is opened by a browser running on a toaster that doesn't have any
of the default fonts installed, it'll be able to render something.
Using Strange Fonts
It's possible to embed fonts directly in to our webpages, allowing us to use a typeface that our users don't have installed. Right now, I'm using "Averia Serif Libre" for this page's headings.
Currently, the best resource for this is Google Fonts, which provides both an enormous library of useful fonts and a helpful wizard to help install and configure these fonts in our pages.
Not Using Strange Fonts
It's important to note, though, that adding a large web font or two can significantly increase the size of a webpage.
One of the major pitfalls of non-system web fonts is that they generally do not render well below about 12pt.
System fonts like Arial or Georgia are designed in such a way that when they get very small,
they can be crammed into a tiny pixel grid to still remain readable.
Most web fonts are not designed with this in mind,
and the process of hammering them into tiny pixel containers can be pretty rough on the final product.
For this reason, it's probably for the best only to use strange fonts for large display text, like headers.
When In Doubt, Just Use Georgia
It's a good font. Look at it. Crisp. Readable. Neutral. Kind. Sassy. Georgia is whatever we want it to be.
Font Size
There are many ways to set font size in CSS;
they all depend on the font-size property.
.one {
font-size: large;
}
.two {
font-size: 10pt;
}
.three {
font-size: 15px;
}
.four {
font-size: 0.5in;
}
.five {
font-size: 120%;
}
.six {
font-size: 2em;
}
<p class="one">Hello world</p>
<p class="two">Hello world</p>
<p class="three">Hello world</p>
<p class="four">Hello world</p>
<p class="five">Hello world</p>
<p class="six">Hello world</p>
These different ways of setting the font size are all examples of CSS Measurements, which are important enough that they deserve a whole topic header to themselves.
CSS Measurements
There are many different ways to provide measurements in CSS.
%, px, in, em, there's twelve in total.
Good thing we have this table:
| % |
A percentage relating to another value, typically the enclosing element —
for example body{ width: 80% } would set the body
to be 80% of the viewport width, whereas p{ font-size: 120% }
would just set the font-size to be 120% of the default font-size. |
Relative |
width: 80%; |
||
| px |
A measurement in screen pixels. While this used to mean 1/96th of an inch, thanks to variable
pixel density screens, px can mean different things based on the device that
it is displayed on.
|
Absolute-ish |
width: 500px; |
||
| em |
A measurement equal to the width of the m in the currently set font. If the font
changes, so does the em.
|
Relative |
width: 25em; |
||
| rem |
A measurement equal to the width of the m in the currently set font of the
page's root element.
|
Relative |
width: 25rem; |
||
| vw | 1% of viewport width. | Relative |
width: 20vw; |
||
| vh | 1% of viewport height. | Relative |
width: 100%; height: 10vh; |
||
| vmin |
Whichever is smaller of vh and vw
|
Relative |
| vmax |
Whichever is larger of vh and vw
|
Relative |
Then there's also in, cm, mm, pt, and pc,
which are all based on real-life measurements, most of which are kind of meaningless when
applied to a computer monitor, so they're all quietly just mapped to various amounts of px.
The question then becomes but which measurements should I use?
But Which Measurements Should I Use?
- Use
%whenever we want to define something relative to something else. - Use
emif we're working with fonts. - Use
pxif we know the exact pixel dimensions of the thing we're working with. - Use
remfor everything else.
Line Height & Line Width
Lines should be between 45 and 90 characters long (including spaces), and in order for lines to be readable, they should be spaced comfortably far apart from one another.
We can set this using the line-height and width properties, respectively,
as well as the measurements that we just learned about.
Let's take this unstyled HTML content:
and add our four CSS rules.
body {
font-family: Georgia, serif; /* font choice */
font-size: 120%; /* font size */
line-height: 1.5em; /* line spacing */
width: 35em; /* line length */
}
I like it! It's no mystery that this textbook uses very similar settings.
Smart Quotes and Special Symbols
One pet peeve of Design Folks is when writers use the wrong characters for things. It bothers them a lot.
For example, this badly written scenario:
The crimes are countless. Well, not countless. But there are definitely at least eight crimes!
- The quote "I'm Spartacus" uses straight quotes instead of angled quotes.
- And a straight apostrophe instead of an angled apostrophe.
- That's a hyphen (-), not an em-dash — which is what we would expect to see, here.
- 45C instead of 45°C? Blasphemy.
- Three periods instead of an ellipsis character…
- (C) is no substitute for ©
- 1/2 could easily read ½
- Some people might consider replacing the ?!?!? with a simple interrobang, ‽, but actually both of these would be incorrect. You get one punctuation mark, writers.
- I'm not sure that Bad Writing ever incorporated into a full company.
Let's update this HTML so that we aren't embarrassed by the bad typography!
<p>
“I’m Spartacus”.
</p>
<p>
Well, that was all well and good — but would he survive
… temperatures of over 45°C?
</p>
<p>
“I can definitely survive exactly 45 degrees of heat!”
</p>
<p>
Darn! But would he survive… ½ of a degree of extra heat?
</p>
<p>
© 2017 Bad Writing Inc.
</p>
That's much better! Well, the writing is still terrible. I don't think using ½ instead of "half" in a sentence is even remotely valid.
That HTML is pretty ugly, though!
There are two potential solutions to this problem:
- If our HTML is encoded properly in UTF-8, we can just include the special characters directly in the file. Many code editors still won't automatically set our curly brace characters for us, though.
- We can attach a JavaScript script to our site that intelligently converts quotes to smart quotes. This script works like magic and I highly recommend it.
Thin, Bold, Uppercase, Small-Caps, and Italics
I'm just going to show you some code and trust you to figure it out.
.bold{
font-weight: bold;
}
.uppercase{
text-transform: uppercase;
}
.caps{
text-transform: capitalize;
}
.lowercase{
text-transform: lowercase;
}
.smallcaps{
font-variant: small-caps;
}
.italic{
font-style: italic;
}
.mixed-bag{
font: bold italic 150% Georgia, serif;
}
Colorful Text
Black is always in — it's trendy, and so slimming — but sometimes we want our text to be a different color. Links, for example, default to a rather hideous blue that we often want to change to match our color scheme.
{kind=link}
Let's imagine we wanted to make every link on our page red, instead of blue. We could do that like so:
a {
color: red;
}
Red is a named color. CSS supports
over 140 different named colors,
including white, blue, aquamarine, snow,
and burlywood.
140 is not really a lot of colors, though! Our monitors can display over 16 million different colors, most of which don't have names.
To tell CSS about a color that isn't one of the 140 named colors, we have to define that color another way.
a {
color: #FF0000;
}
CSS Colors
Colors, as reproduced on a monitor, are represented by three lights — a red light, a green light, and a blue light. When all of the lights are turned all the way up, we get a white pixel. When all of the lights are turned all the way down, we get a black pixel. Blue is created by turning the blue lights all the way up, and leaving the other two lights off. This is Additive Color.
Each light has 256 different possible settings — 0 meaning "off" and 256 meaning "maximum power".
We can set colors by setting these numbers — here's how we would turn our links red using an RGB code:
a {
color: rgb(255, 0, 0);
}
This takes up a lot of space, though. The hex format is a handy format for relaying these values quickly — we convert each number to its hexadecimal representation, mash them all together, and display them like this:
a {
color: #FF0000;
}
A Quick Gray
One thing that's easy to remember is that shades of gray always have the same R, G, and B values.
So we can create very dark grays like #222222 and very light grays like #EEEEEE
without having to think very hard.
Hex Color Tools
When we're looking to create colors that exist beyond the realm of grays, the relationship between hex values and colors can start to get a bit muddy.
Fortunately, countless tools exist to help us with this problem, from simple color pickers to full-on palette generators and complex color wheels.
Hue, Saturation, and Lightness
One common criticism of RGB is that it's very tied to the actual raw implementation of color on a technical level — which produces a scheme that doesn't map easily to our understanding of color.
In an attempt to produce a system that we can understand more easily, RGB can be mapped to Hue, Saturation, and Lightness or Hue, Saturation, and Value — schemes designed to be easier to manage because they more closely approximate how our brains process color.
In the HSL scheme:
- Hue is a number between 0 and 360 that selects the color from a wheel.
- Saturation is a percentage between 0 and 100 that determines how intense the color is, with 0 being "just a shade of gray" and 100 being "dazzling full-color".
- Lightness is a percentage between 0 and 100 that determines how light or dark the color is, with 0 being "black" and 100 being "white"
CSS supports these schemes, although they are not commonly used, as they are a relatively new feature and most tooling still revolves around the old hex-RGB based system.
a {
color: hsl(0, 100%, 50%);
/* 0 is "red",
100% is "full red", and
50% is "not any lighter or darker than standard red" */
}
Opacity
One element of color that's not as frequently considered is the color's opacity.
This determines how transparent the color is. Opacity is the opposite of transparency — so an object with 100% opacity is 0% transparent, and an object that is 100% transparent has 0% opacity. If this seems opaque, your capacity for opacity is limited by your lack of perspicacity, but with tenacity your incapacity can be overcome.
The term for opacity in color is "alpha" — so we can set the
RGBA value to 255, 0, 0, 0.9
to create a color that's entirely red and 10% transparent.
a {
color: rgba( 255, 0, 0, 0.9 );
}
This also works within HSL:
a {
color: hsla( 0, 100%, 50%, 0.9 );
}
We can also do this using the opacity property.
a {
color: red;
opacity: 0.9;
}
Web Typography Summary
Seriously, just use Georgia.
The Box Model
Now that we've defeated the basics of web typography, it's time to start looking in to layout — and layout starts with the box model.
What is the box model, you ask? In CSS, every element is contained within an imaginary box, and the rules for adjusting the size, color, and appearance of those boxes are the box model.
Height & Width
First of all, every element (except for inline elements, which we'll talk about later)
has a width and a height associated with it.
To make these boxes easier to see, our examples are also going to use
background-color, which is a property that sets… well, the background
color.
We can set the width and height using any of the CSS Measurements
we talked about before — em, px, %;
.block-one {
background-color: pink;
width: 300px;
height: 200px;
}
.block-two {
background-color: green;
width: 90%;
height: 5px;
}
<div class="block-one"></div>
<div class="block-two"></div>
Max Height & Max Width
If we're not sure how big the content is going to be, we can set
max-width, min-width, max-height
and min-height instead —
they'll get bigger or smaller with their content, but they won't
get any bigger or smaller than the bounds we set.
In order to help me illustrate this, let me introduce this picture of me, which is exactly 371 pixels wide and 455 pixels tall.

Say hi, me picture!
Looks like he's being shy.
Now, we're going to create a class with a maximum and minimum height, and display it with and without content:
.block-one {
background-color: pink;
max-width: 300px;
max-height: 300px;
min-width: 30px;
min-height: 30px;
}
<div class="block-one"></div>
<div class="block-one"> <img src="images/classam.png"> </div>
What can we divine from this example?
-
Elements want to be as wide as they can. The block with no content
has a
min-widthof30pxand amax-widthof300px, and it's300pxwide. -
Elements do not want to be tall. The block with no content
has a
min-widthof30pxand amax-widthof300px, and it's30pxtall. -
Despite the fact that that image is greater than
300pxin size in both directions, it's leaking out of its container and taking up all kinds of space.
Wait, what?? How? I don't understand how that picture is bigger than it's containing element. Is it stretching it?
We can understand this better by making that image partially transparent.
.block-one {
background-color: pink;
max-width: 300px;
max-height: 300px;
min-width: 30px;
min-height: 30px;
}
.block-one img{
opacity: 50%;
}
<div class="block-one"> <img src="images/classam.png"> </div>
The image isn't stretching its containing element — it just hits the edge and keeps on going!
Overflow!
Can we arrest this rogue element? Contain it within our mighty block-one
element?
Yes, of course we can! We can tell it how to deal with elements that overflow using
the... overflow property.
.block-one {
background-color: pink;
max-width: 200px;
max-height: 200px;
overflow: hidden;
}
.block-two {
background-color: pink;
max-width: 200px;
max-height: 200px;
overflow: scroll;
}
.block-three {
background-color: pink;
max-width: 200px;
max-height: 200px;
overflow-x: hidden;
overflow-y: scroll;
}
<div class="block-one"> <img src="images/classam.png"> </div>
<div class="block-two"> <img src="images/classam.png"> </div>
<div class="block-three"> <img src="images/classam.png"> </div>
overflow:hidden takes any content that ventures outside of the containing element and hides it,
whereas overflow: scroll gives the containing element the ability to scroll around in the
large element.
Those pictures are totally under control!
The Background Of A Box
Sometimes images are part of the content of our page, and if that's the case,
those images should be included as an img HTML
tag — but sometimes images are part of the style of our page, and if that's
the case, those images should be included as part of the page's stylesheet.
But instead of styling a box with a flat background color, we can style a box with a background image, allowing us to drop an image in to our stylesheet.
.my-amazing-face {
background-image: url('images/classam.png');
width: 371px;
height: 455px;
}
<div class="my-amazing-face"></div>
We can also background-repeat images — like this
handsome ring pattern.
With background-repeat set to repeat, even if the background image is smaller
than the containing element, it will tile itself all the way to the edges.
body {
background-image: url('images/chapter3/circles-and-roundabouts.png');
background-repeat: repeat;
}
div {
background-color: white;
width: 200px;
}
<div> Hey there. </div>
Padding
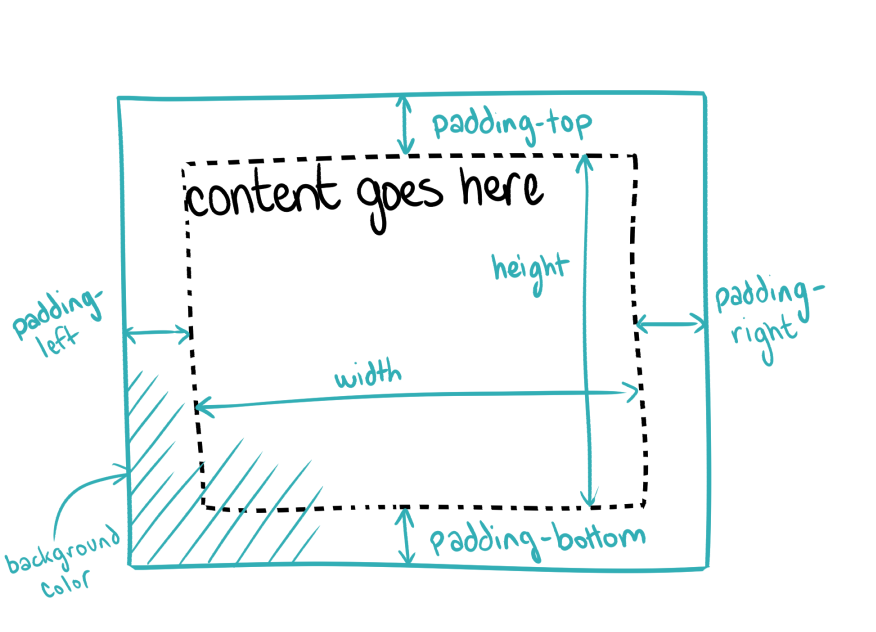
Our content extends to the very edge of our box — which is sort of
ugly, honestly. Fortunately, we can use padding to extend
the box out beyond the edges of the content.
body{
background-color: #333333;
}
blockquote{
background-color: #DDDDDD;
width: 250px;
padding-top: 20px;
padding-left: 20px;
padding-right: 20px;
padding-bottom: 20px;
}
.no-padding{
padding: 0;
}
<blockquote>
Most software today is very much like an Egyptian pyramid with millions
of bricks piled on top of each other, with no structural integrity,
but just done by brute force and thousands of slaves.
— Alan Kay
</blockquote>
<blockquote class='no-padding'>
if you ever code something that "feels like a hack but it works,"
just remember that a CPU is literally a rock that we tricked into thinking
— @daisyowl
</blockquote>
Look at that sweet padding!
Looks like TRBL
Entering padding-top, padding-right, padding-bottom
and padding-left every single time that we want to set the padding on an
element can be a little wordy. Fortunately, there are some shortcuts that we can use to
set the padding quickly.
We can fold all four of these into one padding property, so long as we
remember the order: Top, Right,
Bottom, Left.
body{
background-color: #333333;
}
blockquote{
background-color: #DDDDDD;
padding: 100px 200px 30px 0; /* top right bottom left */
width: 250px;
}
<blockquote>
Java is to JavaScript what Car is to Carpet. — Chris Heilmann
</blockquote>
Of course in many situations, we want to set the same padding in all four directions.
For that, there's an even easier shortcut: we just pass one measurement to the padding property.
body{
background-color: #333333;
}
blockquote{
background-color: #DDDDDD;
padding: 30px;
width: 250px;
}
<blockquote>
"What one programmer can do in one month,
two programmers can do in two months." — Fred Brooks
</blockquote>
Borders
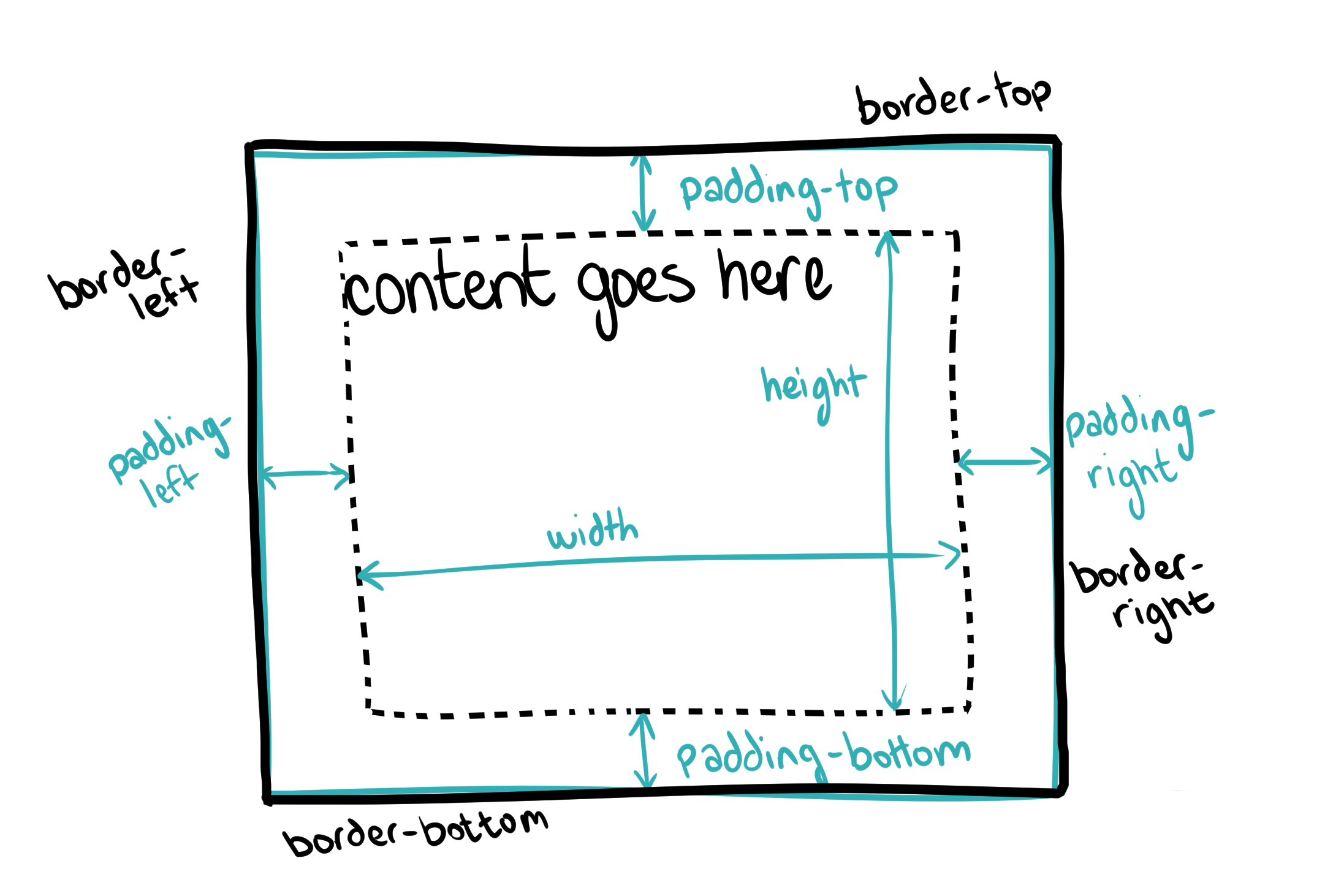
Beyond the edge of the padding lives the border.
The border is an impenetrable wall between the background-color
and the rest of the page.
We must never go beyond the wall. It is cold there.
By default, the border is invisible, but we can make it visible
with the awesome power of various border properties.
body{
background-color: white;
}
blockquote{
width: 250px;
background-color: #DDDDDD;
padding: 30px;
border-top: 2px solid #222222;
border-left: 5px solid blue;
border-right: 4px dashed black;
border-bottom: 10px dotted teal;
}
Each of those border properties came with a width (in the CSS measurement of our choice), a line-type, and a color. The border needs all three to render properly.
Like with padding, if we know all four directions are going to be the same, we can
save ourselves some typing, like so:
blockquote{
width: 250px;
background-color: #DDDDDD;
padding: 30px;
border: 2px solid black;
}
A Gentle Roundness About The Exterior
We can also gently round off the corners of our border with border-radius
blockquote{
width: 250px;
background-color: #DDDDDD;
padding: 30px;
border: 4px solid black;
border-radius: 10px;
}
The larger the measurement in the border-radius, the more rounded the edges
will be, until the element itself is totally round.
blockquote{
width: 75px;
height: 75px;
background-color: #DDDDDD;
padding: 30px;
border: 4px solid black;
border-radius: 200px;
}
Margins
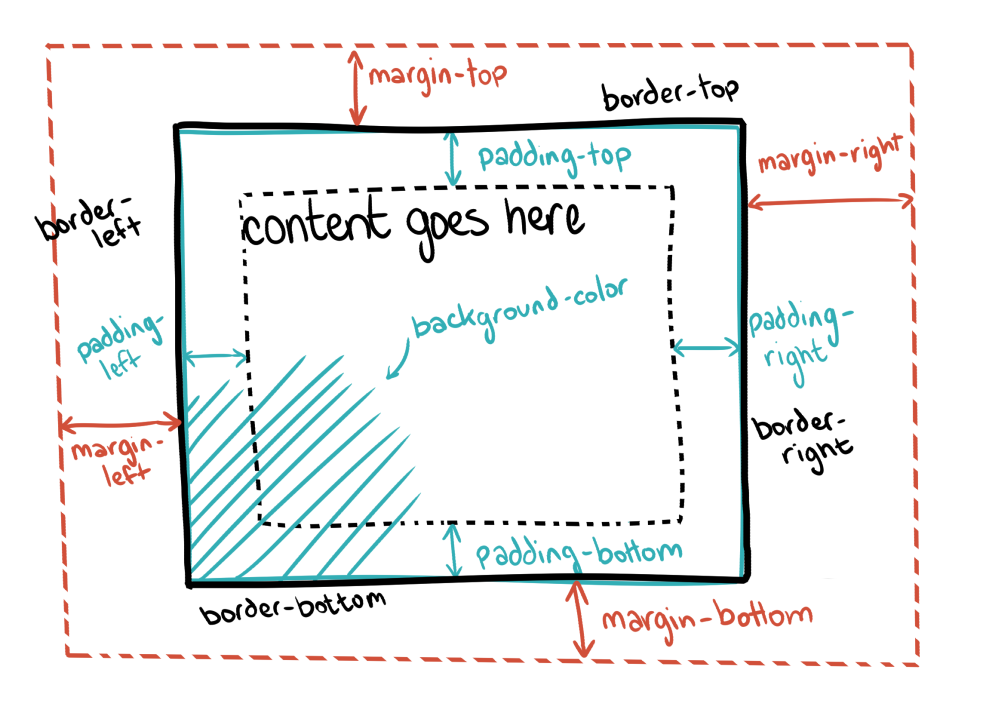
Beyond the padding and the border wall lie the margins. The margins are for spacing — they define a no-man's land between this element and other elements.
blockquote{
background-color: #DDDDDD;
padding: 30px;
border: 4px solid black;
margin-top: 50px;
margin-left: 50px;
margin-right: 50px;
margin-bottom: 50px;
}
Of course, like with padding, we can present these arguments in TRBL
order or combine them into one argument.
blockquote{
margin: 10px 50px 10px 50px;
}
blockquote{
margin: 50px;
}
Centering Content With Auto Margins
If we know the width of an element, and we want to
horizontally center it, we can set the margin-left and margin-right
to auto, and the browser will automatically figure out how to set the margins
such that the element is horizontally centred.
I can't recommend this technique enough — one of the easiest website layouts is simply a single column of readable text, and this trick gives it to us easily. It's how this text stays in the center of the page.
.sassy{
width: 500px;
margin: auto;
background-color: #ccc;
border: 2px solid black;
padding: 20px;
}
blockquote{
width: 300px;
margin: 20px auto 20px auto;
padding: 20px;
background-color: #333;
color: white;
}
<div class="sassy">
<blockquote>
"The best programs are the ones written when
the programmer is supposed to be working on something else."
— Melinda Varian
</blockquote>
<blockquote>
"One accurate measurement is worth a thousand expert opinions."
— Grace Hopper
</blockquote>
</div>
Remember when we talked about how elements want to be as wide as they can
be horizontally, but they want to be as short as they can be vertically?
That's why we can use margin: auto; to center an element
horizontally
but not vertically.
Using margin: auto; vertically is the equivalent of setting margin: 0;.
Margin Collapse
One of the tricky things about margins is that they can overlap with one another.
Let's imagine that we have two elements, one after the other, one with
margin: 25px and one with margin: 35px. How much space would
we guess is between them?
The first answer that would come to mind is 60px — the sum of
the two, but this would be incorrect, because they overlap. In fact, the
elements would only be 35px apart.
A Diagram Of That Thing I Just Said
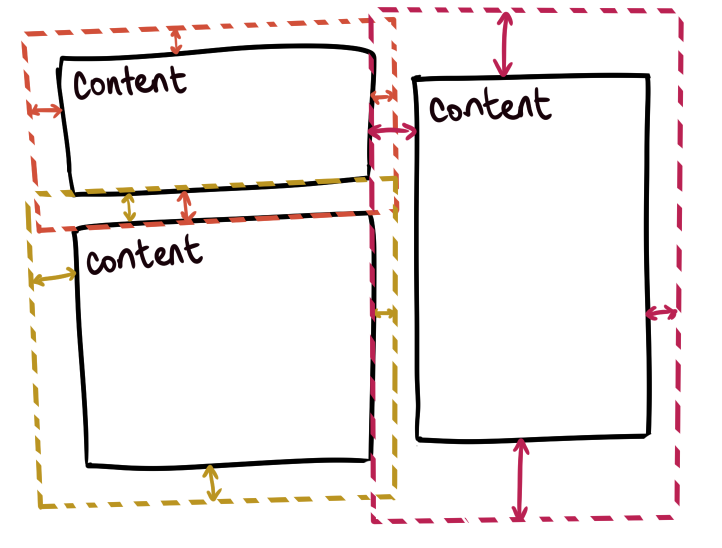
While "Margin Overlap" would be a good name for this, apparently it is called "Margin Collapse" instead.
Divisions, Sections, & Asides (Again)
The box model is a really powerful abstraction for putting boxes around things, which is, at least for now, our most powerful layout technique.
Sometimes, though, we need to put a box around a group of HTML elements that aren't grouped together naturally.
Fortunately, for cases like that, we have our old friend div,
an element that, like vodka or porridge, does not have
any flavor of its own, instead existing just so that we can add our own
flavors to it.
<div class="sassy">
<blockquote>
"That’s what’s cool about working with computers. They don’t argue,
they remember everything and they don’t drink all your beer." — Paul Leary
</blockquote>
<blockquote>
"Think about it; and think about it carefully.
Nothing happens in our society without software. Nothing." — Uncle Bob Martin
</blockquote>
</div>
<blockquote>
"As developers, we are often one of the last lines of
defense against potentially dangerous and unethical practices." — Bill Sourour
</blockquote>
At first glance, it may appear like that div has done nothing. And… it hasn't!
It won't do anything until we apply some style to it.
.sassy{
width: 350px;
font-family: Georgia, serif;
font-size: large;
margin: auto;
}
So, div is great for grouping stuff together.
There's also section and aside. They're… just other names
for div.
Inline vs. Block Elements
In the criminal justice cascading style system, the people elements are
represented by two separate yet equally important groups. The block elements
which are stacked on top of one another, and the inline elements which are stacked
next to one another.
Inline elements are things like links and emphasis — things that are expected to be within a paragraph.
Some properties, like width, don't work on inline elements.
| Block Elements | display: block; | div, h1-h6, p, ul, ol, li, dl, table, blockquote, form, pre |
|---|---|---|
| Inline Elements | display: inline; | a, strong, em, img, br, input, code, span |
| Invisible Elements | display: none; | style, link, meta |
If we have an inline element that we want to make into a block element, we can use display: block.
If we have a block element that we want to make into an inline element, we can use display: inline.
span is to inline elements what div is to block elements — a featureless
element to apply our own styles to.
Let's use display:block and the box model to turn an a link into a button!
a{
display: block;
width: 200px;
font-family: Georgia, serif;
font-size: large;
font-weight: bold;
padding: 20px 50px 20px 50px;
border: 2px solid #333;
border-radius: 50px;
color: #333;
text-decoration: none;
text-align: center;
}
a:hover{
border: 2px solid darkblue;
color: darkblue;
}
<a href="https://twitter.com/classam">@classam</a>
Let's look at that again, but without display:block.
Floats
Boxes in CSS — div, p —
usually stack on top of one another.

Sometimes, though, we want to have an element sit to the left or to the right of other elements.
This image, for example, is a parade float that has been floated to the right, with float: right;
We can also float this image to the left, with float: left;
CSS Comments
Wait wait wait! Hold the presses! We didn't want the element that we floated to the left to push that
section header! We wanted it to push the p text, but not the h2 of the
section header.
In order to stop floated elements from pushing elements around, we can use clear: both
on the element that we want to be un-pushable.
Let's try this again, but this time we'll set clear:both on the h2 header for CSS Comments.
CSS Comments Again
Are we safe? Can we talk about comments, now? Yeah? Okay, let's continue.
Sometimes we want to comment out large blocks of CSS code, or add comments to our CSS.
The only way to comment in CSS is /* like this */
/*
a{
display: block;
width: 200px;
font-family: Georgia, serif;
font-size: large;
font-weight: bold;
padding: 20px 50px 20px 50px;
border: 2px solid #333;
border-radius: 50px;
color: #333;
text-decoration: none;
text-align: center;
}
*/
a:hover{
border: 2px solid darkblue; /* this is a comment */
color: darkblue;
}
Chapter 3 Summary
In this chapter we learned about:
- Stylesheets
- CSS selectors
- CSS rules
- The Box Model
- Web typography
- Basic layout
There's lots more to learn about CSS, but I think it's best to save that for a future chapter.
Chapter 4: Building A Web Server
We need to get our website online, somehow! While there are lots of online services that make this easy, we're going to start the unnecessarily hard way and run a web server on our own computer.
By tradition, when computering, our first program is always a program to print out 'hello, world'.

You could, of course, broadcast the message "hello, world" by tattooing it on your arm, as I have, but perhaps we should start with a less permanent solution to the problem.
This chapter is going to cover a lot of topics very loosely in order to get us to a workable initial state. Don't worry — we'll be covering everything, in depth, eventually.
We're going to be doing everything — absolutely everything — from a Linux command line.
Both of these choices — Linux, and the command line — might seem a little strange. Let's dig into them a bit.
Linux
Fully half of web programming is server programming. In order to program a server, we're going to need a server — a computer that stays online all the time and responds to client requests.
We could use our home computer as a server, but:
- Windows and Mac operating systems have an awkward tendency to reboot themselves to install security updates and add features, and this is not optional.
- A home computer has all of its security defaults set in a way that would be appropriate for a computer on a home network, not a computer exposed to the tireless onslaught of the public internet.
- Unless we pay our ISP extra for a static IP address, our home's IP address changes regularly, which means that it will be difficult to find our computer.
- Our home computer likely contains our own, personal, private information.
- Doing other stuff on our home computer, like opening 80 browser tabs while playing video games, could affect the performance of our server.
- Unless we happen to have a home fibre connection, it's likely that we're on an asymmetric connection to the internet — with downloads much faster than uploads. For a server, though, it is the upload speed that matters; serving a lot of traffic from our home internet connection would be like trying to operate a Denny's through a foot-wide hole — possible, but frustrating once we have more than one or two customers.
These are not insurmountable problems, and building a home server out of a spare computer is a fun and instructive project that I highly recommend.
With the home computer out as a server option, that leaves us renting server time from someone else.
There are lots of reasons that we might choose Linux over Windows if we're planning on running a server for a long time. Linux is lightweight. Linux is secure. Linux is able to stay online for a very long time. The reason for Linux's popularity as a server is very simple, though: Linux is free, which generally makes server Linux the most cost-effective option.
"It's a UNIX system! I know this!"
Linux, like Mac OS X, is based on Unix, an operating system with an almost half-century of history, only some of which involves velociraptors. That half-century can be a double-edged sword — the reason for strange design decisions is often shrouded in some ancient obscure keyboard layout.
Linux Distributions
One confusing thing about Linux is that we can't just crack open a laptop and start running Linux on it — in fact, Linux really refers to The Linux Kernel, which is the tiny beating heart of the operating system.
There are lots of things that we think of as part of an operating system — the window system, a desktop environment, the software that comes pre-installed on the system, device drivers, installers, Minesweeper — but the Linux Kernel doesn't come with any of these things.
So, the complete kit required to make a computer actually do computer things is called a Linux Distribution.
Popular distributions include Ubuntu, Red Hat/Fedora, Mint, Slackware, and Arch.
Different distributions focus on different priorities. Some, like Mint, focus on being easy to use as a desktop OS. Arch is highly configurable and optimizable, and popular with the sort of people who drive a 1996 Nissan 300ZX Turbo with a gigantic aftermarket spoiler and undercar lights.
Ubuntu started out resolutely trying to conquer the desktop PC market, but after a decade of mostly failing to do so, has seemingly embraced its position as a competitive and pretty comprehensive server operating system. I like Ubuntu, a lot, and it's the distribution I'm going to be using as an example distribution.
The Command Line & The Secure Shell
Most systems work is still done with the command line.
While I'd love to say that this is because the command line is inherently superior to all other methods of interaction with a computer, the actual reasons are simple:
- It's easier to write a command line program than a GUI program.
- SSH
SSH, or Secure Shell, is one of the most important tools in our web programming arsenal. SSH is a tool allowing for remote control of computers.
Most Linux distributions run the SSH daemon in the background, all the time, and it's possible to log in to the computer directly with a username and password.
But the SSH interface to a Linux computer doesn't come with any fancy doodads or graphical user interfaces. Nope, dad-gummit, we have to control the system by pulling up our suspenders, tying an onion to our belts, walking uphill both ways, and using the command line interface.
Let's Get This Terrible Party Started
First and foremost, we are going to need access to a command line.
If we're running Mac OS X, we can get to a command line, right now, by opening the "Terminal" program — although downloading iTerm2 gets us tabs and splits.
If we're running Windows, we can download Git. We're going to need Git anyways, it's the most widely used source control tool on the market, but it also comes with the easiest to configure unix-like console available in Windows. Move over, Cygwin.
If we're not in a hurry, we also might spend some time configuring ConEmu to work with Git Bash. This gets us the tabs and the splits.
Code Directory & Project Root
Somewhere on our computer is our home directory. This is the root
for all of our personal files. In Windows, my home directory lives at
C:\Users\Curtis, whereas in Mac OS X, the home directory lives
in /users/curtis.
I'm fond of creating a directory, code, under the home root, as
my project root. Every different project I'm working on lives in this directory.
Then, I configure my terminal to open this directory when it starts up.
Let's open our terminal — be it Terminal, iTerm2, Git Bash, or ConEmu.
dat's some good terminal
We're staring a command prompt in the face. That $
means that the terminal is ready for us to enter a command.
Let's Putter Around In The Terminal A Bit
I'm excited! I get to tell you about the most important shell commands!
Let's start by asking where we are, using the print working directory command,
pwd.
curtis@SMOKESTACK ~/code $ pwd /c/Users/curtis/code
Tilde Swinton
So, we're at /c/Users/curtis/code, but the terminal says that
we're at ~/code. What's the deal?
~(tilde) is shorthand for "home".
Since our home is /c/Users/curtis, ~/code
is shorthand for /c/Users/curtis/code.
MSYS
Follow-up question: why is it /c/Users/curtis/code
and not C:\Users\curtis\code?
Simulating Bash on Windows requires a layer to translate Windows concepts into vaguely-Linux-shaped concepts. This is provided by MinGW — Minimalist GNU for Windows — and MSYS, which is a collection of utilities like Bash ported to run on MinGW.
Linux doesn't support lettered-drive roots like C:, instead prefering
to have a single root for all drives, /.
Linux also uses forward slashes instead of backslashes.
MSYS and MinGW do this conversion for us, but the differences between Windows and Linux are going to continue to bite us all the way throughout this journey.
Mac OS X, being built on top of a Unix system called "Darwin", doesn't suffer from these problems.
Terminal Commands
Using the change directory command, cd, we can change
our directory.
curtis@SMOKESTACK ~/code $ cd ~ curtis@SMOKESTACK ~ $ pwd /c/users/curtis
Look, we're home, now!
We can navigate to a specific directory:
curtis@SMOKESTACK ~ $ cd / curtis@SMOKESTACK / $ cd /etc curtis@SMOKESTACK /etc $
And we can use ls to display the contents of a directory:
curtis@SMOKESTACK /etc $ cd ~ curtis@SMOKESTACK ~ $ ls AppData Application Data ConEmu Contacts Cookies Creative Cloud Files Embarrassing Pornography Even More Embarrassing Pornography Seriously, Goats and Stuff Desktop Documents Music NTUSER.DAT _vim _viminfo _vimrc code pip vimfiles
Whoa. There's a lot of stuff in my home directory.
If there's no code directory in here, yet, we can make one, with mkdir
curtis@SMOKESTACK ~ $ mkdir code mkdir: cannot create directory 'code': File exists
That doesn't work, because in my case, the code directory already exists.
Here's a good trick. Type in cd c and then hit the tab key.
curtis@SMOKESTACK ~ $ cd code curtis@SMOKESTACK ~/code $
The terminal should auto-complete to the first thing that starts with a 'c'. If you press tab again, it'll auto-complete to the second thing that starts with a 'c'. This is a very useful tool.
All this computer hacking is making me thirsty. I think I'll order a TAB.

Let's create a directory for our hello world program.
curtis@SMOKESTACK ~/code $ mkdir hello_world curtis@SMOKESTACK ~/code $ ls hello_world
Now let's delete that directory and then recreate it, just to be contrary.
curtis@SMOKESTACK ~/code $ rmdir hello_world curtis@SMOKESTACK ~/code $ ls curtis@SMOKESTACK ~/code $ mkdir hello_world curtis@SMOKESTACK ~/code $ ls hello_world
We can use cd to jump in to the folder we've just created, and we can also
use cd with the special shortcut .. to go up a level.
curtis@SMOKESTACK ~/code $ cd hello_world curtis@SMOKESTACK ~/code/hello_world $ cd .. curtis@SMOKESTACK ~/code $ cd .. curtis@SMOKESTACK ~/ $ hello_world
That feels like a pretty solid introduction to the command line. With these simple tools we can zip around the filesystem creating directories like a pro!
Curtis's Big Sexy Terminal Cheat Sheet
ls | list the contents of a directory |
|---|---|
cd | change the directory |
pwd | tell me what directory I'm in |
mkdir | make a directory |
rmdir | remove a directory |
touch | make a file |
cat | print a file |
rm | remove a file |
cp | copy |
mv | move |
sudo | i am an admin, let me do this thing |
For a more in-depth introduction to Unix/Linux, you could always visit this Unix Tutorial for Beginners.
Installing Ubuntu
This used to be a process that involved either running both Ubuntu and Windows/Mac OS X on our primary computer, and switching from one to the other when we boot up the computer — or, finding a junky old computer from around the house and installing Ubuntu on that.
With Virtual Machines, though, it's possible to run Ubuntu from within our primary operating system. So we should definitely do that. In fact, the toolset for doing this has become so easy to use that I've started running a different virtual machine for every project I'm working on.
The tools that make this easy and free are VirtualBox and Vagrant. Download and install these programs.
VirtualBox & Vagrant
VirtualBox is software to run virtual machines. We could get away with just using VirtualBox in our quest to install Ubuntu, but that would take a lot of effort and clicking.
Vagrant is a wrapper around VirtualBox that provides a very hackable command line interface and a gigantic repository of pre-created operating system images. Installing an operating system with Vagrant can be as easy as just picking it out of a catalogue and modifying a text file.
One of the things I like most about Vagrant is that it's possible to configure the entire operating system automatically. Instead of laboriously hand-configuring the operating system every time we move to a new machine or accidentally bork a database, we can just incinerate the virtual machine clean and summon a new one.
Let's go back to our new 'hello_world' directory and type in vagrant init
curtis@SMOKESTACK ~/code $ cd hello_world curtis@SMOKESTACK ~/code/hello_world $ vagrant init A `Vagrantfile` has been placed in this directory. You are now ready to `vagrant up` your first virtual environment! Please read the comments in the Vagrantfile as well as documentation on `vagrantup.com` for more information on using Vagrant.
vagrant init creates for us a Vagrantfile. This file
describes all of the important details about the operating system we are about
to create — which Linux distribution we want, networking details, how much
RAM it gets to use, and even, if we configure it right, the instructions for
setting up all of the software that runs on the operating system.
Now it's time to open up the Vagrantfile in a text editor.
# -*- mode: ruby -*-
# vi: set ft=ruby :
# All Vagrant configuration is done below. The "2" in Vagrant.configure
# configures the configuration version (we support older styles for
# backwards compatibility). Please don't change it unless you know what
# you're doing.
Vagrant.configure(2) do |config|
# The most common configuration options are documented and commented below.
# For a complete reference, please see the online documentation at
# https://docs.vagrantup.com.
# Every Vagrant development environment requires a box. You can search for
# boxes at https://atlas.hashicorp.com/search.
config.vm.box = "base"
# Disable automatic box update checking. If you disable this, then
# boxes will only be checked for updates when the user runs
# `vagrant box outdated`. This is not recommended.
# config.vm.box_check_update = false
# Create a forwarded port mapping which allows access to a specific port
# within the machine from a port on the host machine. In the example below,
# accessing "localhost:8080" will access port 80 on the guest machine.
# config.vm.network "forwarded_port", guest: 80, host: 8080
# Create a private network, which allows host-only access to the machine
# using a specific IP.
# config.vm.network "private_network", ip: "192.168.33.10"
# Create a public network, which generally matched to bridged network.
# Bridged networks make the machine appear as another physical device on
# your network.
# config.vm.network "public_network"
# Share an additional folder to the guest VM. The first argument is
# the path on the host to the actual folder. The second argument is
# the path on the guest to mount the folder. And the optional third
# argument is a set of non-required options.
# config.vm.synced_folder "../data", "/vagrant_data"
# Provider-specific configuration so you can fine-tune various
# backing providers for Vagrant. These expose provider-specific options.
# Example for VirtualBox:
#
# config.vm.provider "virtualbox" do |vb|
# # Display the VirtualBox GUI when booting the machine
# vb.gui = true
#
# # Customize the amount of memory on the VM:
# vb.memory = "1024"
# end
#
# View the documentation for the provider you are using for more
# information on available options.
# Define a Vagrant Push strategy for pushing to Atlas. Other push strategies
# such as FTP and Heroku are also available. See the documentation at
# https://docs.vagrantup.com/v2/push/atlas.html for more information.
# config.push.define "atlas" do |push|
# push.app = "YOUR_ATLAS_USERNAME/YOUR_APPLICATION_NAME"
# end
# Enable provisioning with a shell script. Additional provisioners such as
# Puppet, Chef, Ansible, Salt, and Docker are also available. Please see the
# documentation for more information about their specific syntax and use.
# config.vm.provision "shell", inline: <<-SHELL
# sudo apt-get update
# sudo apt-get install -y apache2
# SHELL
end
Picking a Box
In order to boot up an operating system, first, we have to pick a base box — this is the blank, untouched, pristine operating system that we are going to be working with.
A catalogue of base boxes exists here.
We're going to choose ubuntu/xenial64.
The line in the Vagrantfile pertaining to boxes will read:
# Every Vagrant development environment requires a box. You can search for
# boxes at https://atlas.hashicorp.com/search.
config.vm.box = "ubuntu/xenial64"
Forwarding Port 80
The virtual machine is going to be running a web server (spoiler alert) on port 80. The only problem with that? The ports on the virtual machine aren't accessible by default. We need to write a rule to connect a port on our outer machine to a port on the virtual machine.
By convention, 8080 is popular port for developing
HTTP services,
so we're going to use that.
The VagrantFile already had this option ready for us — all we have to do
is remove the # character to turn the line from a comment into
real code.
# Create a forwarded port mapping which allows access to a specific port
# within the machine from a port on the host machine. In the example below,
# accessing "localhost:8080" will access port 80 on the guest machine.
config.vm.network "forwarded_port", guest: 80, host: 8080
Syncing a Folder
This is a more advanced feature, but one that's going to allow us to edit our codebase on the virtual machine with a graphical text editor on our host machine, and that seems like it's going to be worth the effort.
First of all, let's create a folder to sync.
curtis@SMOKESTACK ~/code/hello_world $ mkdir html
Then, let's sync that folder to a location within the virtual machine.
We could choose just about any location, but if we were to do something like "accidentally sync over a whole lot of important system files", we would be in for a world of trouble.
One spot that's generally safe is /home/ubuntu/something.
Vagrant boxes usually come with one user operating on them, already.
This one comes with a user named ubuntu, and that user's home
directory is /home/ubuntu, which means we can put anything
in there that we want.
# Share an additional folder to the guest VM. The first argument is
# the path on the host to the actual folder. The second argument is
# the path on the guest to mount the folder. And the optional third
# argument is a set of non-required options.
config.vm.synced_folder "html", "/home/ubuntu/html"
Pull the Lever, Kronk
Save the Vagrantfile and we're ready to get started!
Let's turn the Virtual Machine on, with vagrant up.
curtis@SMOKESTACK ~/code/hello_world $ vagrant up Bringing machine 'default' up with 'virtualbox' provider... ==> default: Checking if box...
Eventually a mountain of output will go by.
If that process went off without a hitch, we are good to go.
Logging In
Finally, we can log in to our newly created Ubuntu operating system
with the command vagrant ssh.
curtis@SMOKESTACK ~/code/hello_world $ vagrant ssh Welcome to Ubuntu 16.04.2 LTS (GNU/Linux 4.4.0-78-generic x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage Get cloud support with Ubuntu Advantage Cloud Guest: http://www.ubuntu.com/business/services/cloud 0 packages can be updated. 0 updates are security updates. Last login: Thu May 18 02:31:20 2017 from 10.0.2.2 ubuntu@ubuntu-xenial:~$
This is a whole new command line. The command line of the Ubuntu Virtual Machine. We've got an Ubuntu server running inside our computer!
Take a moment for a brief celebration.
Installing a Web Server
We're not done, yet. Our server is running, yes, and we've made sure that, if it listens on port 80, we can connect to it.
One problem, though — the server isn't listening on port 80. This is just a server, right now. We need to install a web server on our server server.
We can do that with the command sudo apt-get install nginx.
Whoa. There's a lot of stuff happening in that command. Let's unpack that a bit!
sudo
sudo stands for "superuser do".
Linux is, by nature, a multi-user operating system. It's designed to have many users logged in at once.
In order to keep users from being able to access each other's files, each file has a set of permissions that defines who is able to see it, and many system functions are locked down so that common users can't touch them.
sudo is a way of saying "I am the administrator and I can do whatever I like".

Not everybody has access to sudo — only admin users.

Superuser access is required to install software which is what we wanted to to, here.
apt-get install
apt-get is the command line interface to the
advanced packaging tool,
which — and this is going to seem pretty magical if you're used to the way
that Windows does things — allows you to install any Ubuntu program, automatically,
with a single command.
Seriously. Want vim? Type sudo apt-get install vim. Want to install a program
that pipes your command output through
ASCII-art cows? sudo apt-get install cowsay.
Want a steam locomotive? sudo apt-get install sl.
nginx
Nginx is a fast, lightweight HTTP server. It can also be configured to do a few other fun tricks, like act as a load balancer or reverse proxy, but right now we're interested in just using Nginx to serve some web page.
sudo apt-get install nginx
Well, that's enough explanation. Let's get to it!
ubuntu@ubuntu-xenial:~$ sudo apt-get install nginx
This will ask us to confirm it by pressing y, then chug along
and eventually stop chugging. At this point, we have a web server!
Prove it
Don't believe me? Open a browser and visit localhost:8080
Egads! It worked!
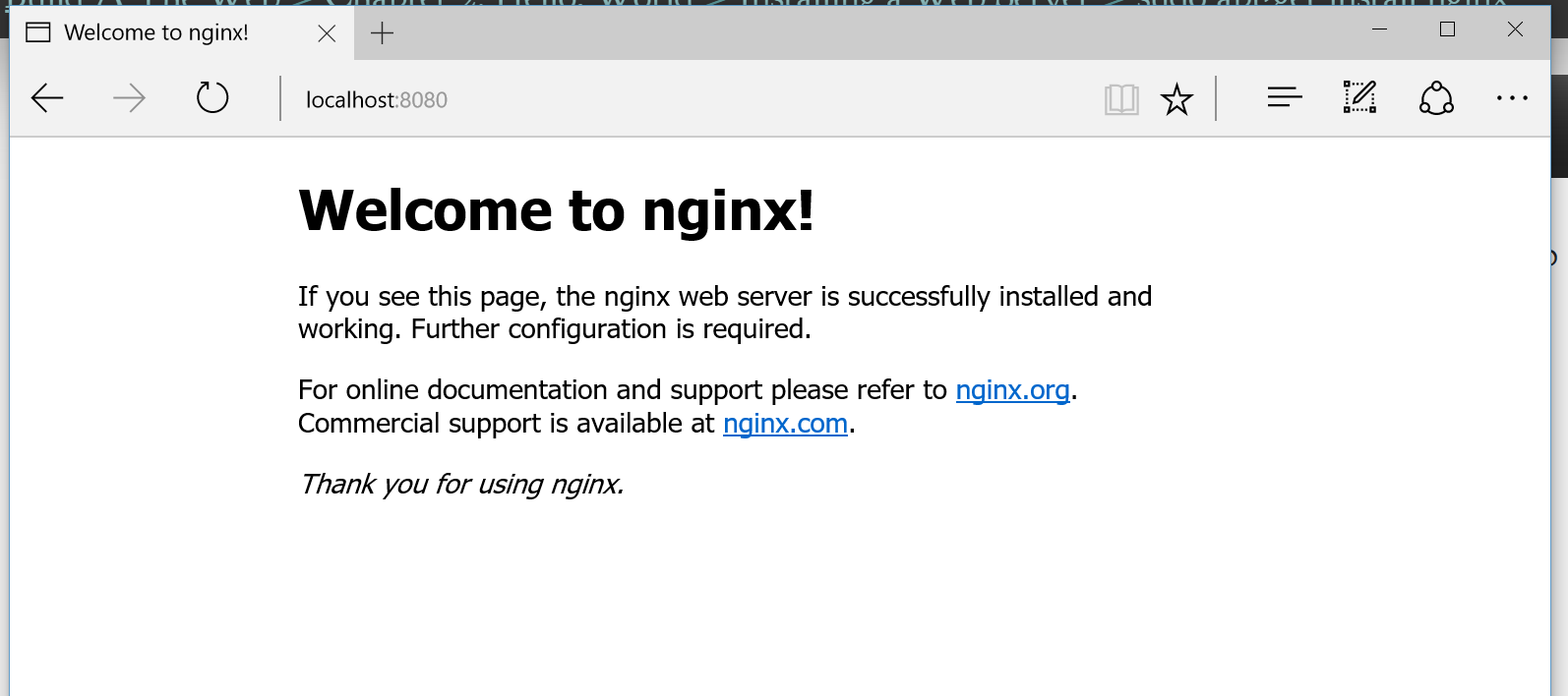
localhost
This is a shortcut! localhost is a domain that always
resolves to 127.0.0.1,
which is a special IP address that always resolves to this computer, the
one that I am using right now.
:8080
Earlier, I mentioned that the port that your browser connects to is always
the default port for the protocol — in the case of HTTP, that's 80.
However, when we created the Virtual Machine, we specified that port 80 on the
Virtual Machine should correspond with port 8080 on the host machine.
When we enter a domain name, we can always add a colon and the port number to specify that we're connecting to a non-standard port.
Creating a Basic HTML Document
Now that we've got a server running an HTTP server, we need something to serve.
We're going to go into more detail about HTML later,
but for now, let's create a very simple file, index.html
and put it in our ~/code/hello_world/html
directory on our host computer
<!-- I go in ~/code/hello_world/html/index.html -->
<html>
<head>
<title>hello, world</title>
</head>
<body>
<h1>hello, world</h1>
</body>
</html>
This file should now exist at /home/ubuntu/html/index.html on
our virtual machine.
Serving our HTML
By default, nginx serves the contents of a system directory, /var/www/html,
which contains the "hey, you're running nginx" message we saw earlier.
We could just copy our file into /var/www/html, but that's not the
satisfying solution that we want. No, we want to tell nginx to serve
from /home/ubuntu/html rather than /var/www/html
by changing nginx's configuration files!
One problem: nginx's configuration files are deep within the Ubuntu virtual machine, not synced to anywhere on our host machine. We have to edit these configuration files from within the virtual machine.
A Different Kind of Text Editor
Presumably, we're far enough along in the craft of programming to know that a text editor is the software developer's multi-tool, and one's choice of text editor is approximately as emotionally charged and contentious as one's choice of video game console.
But there's a problem — because we're working extensively with SSH, and SSH is a command shell, with no mouse to speak of, we're going to need a text editor that operates entirely from within the shell.
This leaves us, then, with about three different options:
- vim, my favourite, which is cryptic and difficult, but powerful
- emacs, which is even more cryptic and difficult, but even more powerful
- nano, which is quite easy to learn, but offers limited functionality
Nano is Like a Spork

As much as I want to push my pigheaded vim lust on to a new generation of developers, nano is the easiest editor to get started with.
Configuring Nginx
ubuntu@ubuntu-xenial:~$ sudo nano /etc/nginx/sites-available/default
sudo again
Why sudo? Well, /etc/nginx/sites-available/default is a
system file, and we wouldn't normally have access to modify it.
/etc is for config
/etc is the directory that contains the configuration files
for most Linux systems. This is not a very good name.
They might as well have called this directory /you/know/whatever
or /idfk — or maybe, and I'm just spit-balling, here, /config,
but the insane tradition of calling this directory /etc lives on.
/sites-available/default
While the core configuration for nginx lives at /etc/nginx/nginx.conf,
all it does is reference a multitude of other files.
Sometimes I like to throw out all of the default configuration and just dump all
of my configuration directly into nginx.conf, but for this example
we're going to play ball with the rules and instead edit this
other configuration file.
Here's the configuration file:
## /etc/nginx/sites-available/default
##
# You should look at the following URL's in order to grasp a solid understanding
# of Nginx configuration files in order to fully unleash the power of Nginx.
# http://wiki.nginx.org/Pitfalls
# http://wiki.nginx.org/QuickStart
# http://wiki.nginx.org/Configuration
#
# Generally, you will want to move this file somewhere, and start with a clean
# file but keep this around for reference. Or just disable in sites-enabled.
#
# Please see /usr/share/doc/nginx-doc/examples/ for more detailed examples.
##
# Default server configuration
#
server {
listen 80 default_server;
listen [::]:80 default_server;
# SSL configuration
#
# listen 443 ssl default_server;
# listen [::]:443 ssl default_server;
#
# Note: You should disable gzip for SSL traffic.
# See: https://bugs.debian.org/773332
#
# Read up on ssl_ciphers to ensure a secure configuration.
# See: https://bugs.debian.org/765782
#
# Self signed certs generated by the ssl-cert package
# Don't use them in a production server!
#
# include snippets/snakeoil.conf;
root /var/www/html;
# Add index.php to the list if you are using PHP
index index.html index.htm index.nginx-debian.html;
server_name _;
location / {
# First attempt to serve request as file, then
# as directory, then fall back to displaying a 404.
try_files $uri $uri/ =404;
}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
#location ~ \.php$ {
# include snippets/fastcgi-php.conf;
#
# # With php7.0-cgi alone:
# fastcgi_pass 127.0.0.1:9000;
# # With php7.0-fpm:
# fastcgi_pass unix:/run/php/php7.0-fpm.sock;
#}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
}
# Virtual Host configuration for example.com
#
# You can move that to a different file under sites-available/ and symlink that
# to sites-enabled/ to enable it.
#
#server {
# listen 80;
# listen [::]:80;
#
# server_name example.com;
#
# root /var/www/example.com;
# index index.html;
#
# location / {
# try_files $uri $uri/ =404;
# }
#}
This is an awful lot of file to look at, but there's only one line that we're concerned about.
We need to change root /var/www/html; to read root /home/ubuntu/html;,
and then save the file.
Rebooting nginx
That change should do it, but none of our configuration changes will take effect until we reboot nginx.
ubuntu@ubuntu-xenial:~$ sudo service nginx restart
We Did It!
Let's go back to localhost:8080 in a browser.
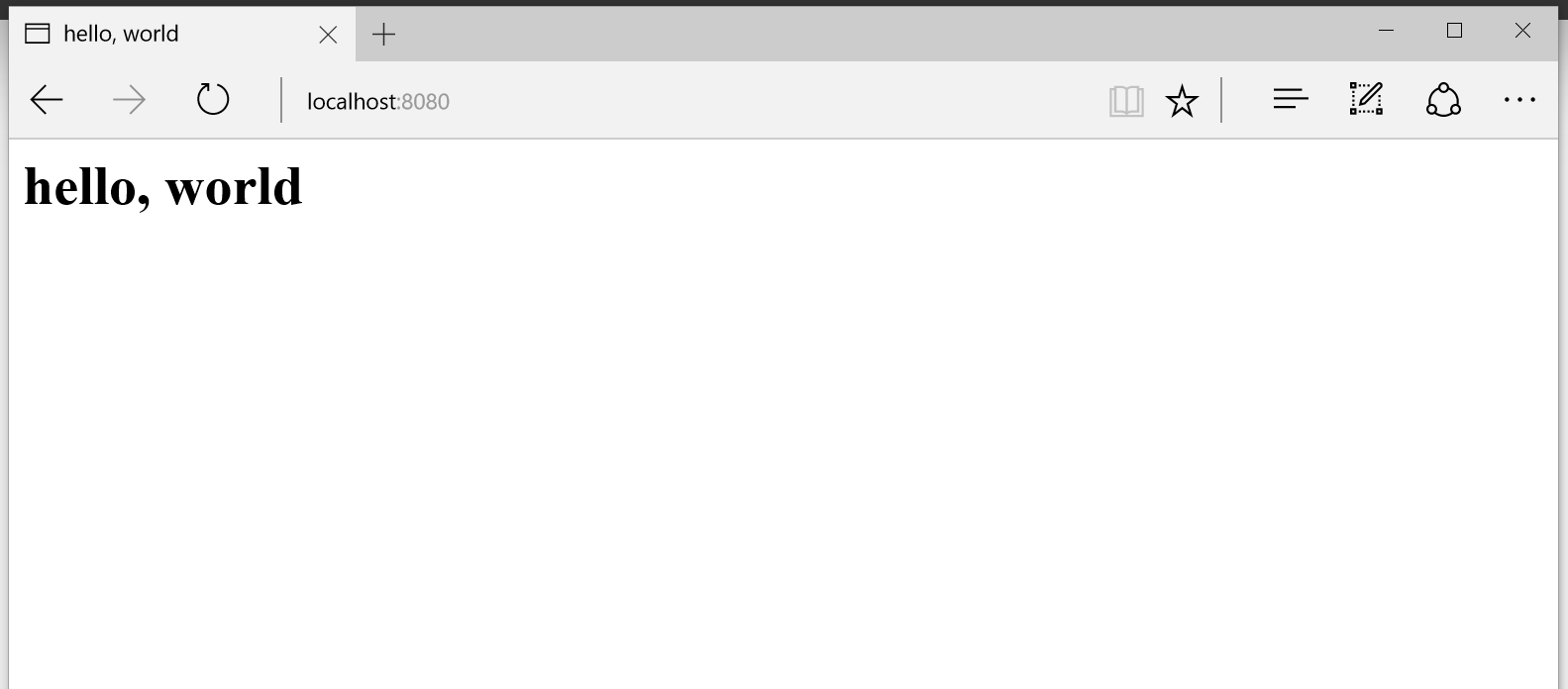
Please attempt to contain your excitement.
Who would have thought that a simple "hello, world" program would take so much effort?
Cleaning Up & Starting Over
We're done, but our Virtual Machine is still running. It'll keep on running, forever. That's the whole point of a server.
We can quit the terminal.
ubuntu@ubuntu-xenial:~$ exit logout Connection to 127.0.0.1 closed. curtis@SMOKESTACK ~/code/hello_world $
But if we check localhost:8080, the server's still running.
The only way to truly kill the server is to plunge a stake through it's heart
turn it off, which we can do with vagrant halt.
curtis@SMOKESTACK ~/code/hello_world $ vagrant halt ==> default: Attempting graceful shutdown of VM...
That killed it.
Let's imagine, though, that we made a serious mistake. While we were working on the operating system we accidentally made a change that ruined everything forever and we don't know how to fix it.
We want to go back to a completely
clean slate, to the good times before we had a Virtual Machine at all.
This is the situation where vagrant destroy is here to purify
our hard drive with its scouring light.
curtis@SMOKESTACK ~/code/hello_world $ vagrant destroy default: Are you sure you want to destroy the 'default' VM? [y/N] y ==> default: Destroying VM and associated drives...
Never again will you trouble our shores with your foul presence, Virtual Machine.
We can always bring it back with vagrant up when we need it again.
Chapter 4 Summary
We've done a lot, to get our web server up and running and serving "hello, world"!
- We installed a command line interface and learned some basics about how to use it.
- We used Vagrant and VirtualBox to install an Ubuntu Linux Virtual Machine on our computer.
- We used sudo and apt-get to install nginx on our server.
- We created a basic HTML file.
- We used nano to change nginx's configuration.
- We rebooted nginx.
- We destroyed the Virtual Machine.
Oh no! This is as far as I've written! Keep track of the project on GitHub for updates!